유튜브 블로그 변환: 영상 하나를 시리즈 글로 쪼개는 파이프라인
유튜브 블로그 변환 한 줄 요약
결론부터. 유튜브 블로그 변환은
자막 추출 -> 한국어 중복 정리 -> 시리즈 분할 -> 사람 검수4단계로 잡으면 돼요. 자막만 옮기면 읽는 글이 아니라 듣는 글이 되기 쉬워서, 명령어·실패 사례·스크린샷 같은 원본 영상 밖 정보를 꼭 얹어야 하죠. 자막이 이미 있는 영상이면 무료 라이브러리부터 시작하고, 서버에서 막히거나 자막이 없으면 API 대안을 붙이면 돼요.
유튜브 영상 하나를 블로그 글로 바꿔준다는 구독형 도구를 몇 개 써봤는데, 결과물이 자막 덩어리라 바로 닫았어요. 읽는 글이 아니라 듣는 글이 되더라고요. 그래서 유튜브 블로그 변환은 요약 문제가 아니라 편집 문제라고 보고 흐름을 다시 짰죠.
자막만 뽑아 대규모 언어 모델에 넣으면 편하긴 한데, 한국어 자동 자막은 같은 문장이 반복되고 문단 경계도 흐려서 그대로는 토큰만 새거든요. 서버에 올리자마자 자막 추출이 막히는 경우도 있고, n8n도 노드 조건을 잘못 보면 세팅부터 꼬여요.
여기서는 그런 삽질을 줄이는 쪽으로 정리했어요. 영상 1개를 글 1개로 억지로 만드는 대신, 검색 의도별로 3~5편 시리즈로 나누는 기준부터 잡을 거예요. 자막 추출, 한국어 중복 정리, 시리즈 분할 프롬프트, 발행 전 검수까지 한 번에 이어갈 거예요.
브리프를 먼저 잡고 싶은 분은 AI 블로그 브리프 자동 생성: 실전 파이프라인 구축기부터 보고 와도 흐름이 잘 붙어요.
핵심은 완전 자동화 욕심을 버리는 거예요. 자막 정리와 초안 뼈대는 기계가 빨리 해주지만, 사실 체크와 실행 예제는 사람이 잡아야 글이 살아나요. 이 분업만 제대로 잡아도 유튜브 콘텐츠 재활용 난도가 확 내려가요.
왜 영상을 블로그 시리즈로 쪼개야 하나
영상 1개를 글 1개로 옮기면 검색 의도가 섞여요. 시리즈로 나누면 제목, H2, 내부 링크, CTA를 각각 또렷하게 잡을 수 있죠.
굳이 한 편에 다 몰아넣을 이유가 있을까요?
유튜브는 말 흐름대로 전개되는데, 검색은 질문 단위로 들어오거든요. 그래서 한 영상 안에 자막 추출, 전처리, SEO 검수, 발행 자동화가 다 들어 있으면 글은 길어지는데 제목은 애매해지죠. 반대로 시리즈로 쪼개면 각 글이 하나의 질문만 잡아서 훨씬 읽히죠.
오디오 원본을 텍스트로 바꾸는 감각은 회의록 블로그 변환: 녹음 파일 하나로 초안까지 20분 파이프라인과 거의 같아요. 다만 유튜브 쪽은 자막 품질 편차와 검색 의도 분리가 더 중요하더라고요.
시리즈 분할 기준은 이 정도로 잡으면 편해요.
- 한 글이 하나의 행동만 시키는지 체크
- 명령어 예제가 1개 이상 들어가야 해요
- 독자 질문이 한 문장으로 정리되는지 체크
- 다음 글로 내부 링크가 자연스럽게 이어지면 성공
| 방식 | 결과 | 장점 | 주의할 점 |
|---|---|---|---|
| 영상 1개 -> 글 1개 | 통짜 가이드 | 빨리 만든다 | 검색 의도가 섞인다 |
| 영상 1개 -> 시리즈 3편 | 문제별 가이드 | 제목과 내부 링크가 또렷하다 | 분할 기준이 필요하다 |
| 영상 1개 -> 시리즈 5편 | 롱테일 대응 | 검색면을 넓힌다 | 검수량이 늘어난다 |
개인적으로 처음엔 한 편짜리 통짜 가이드로 올렸는데, 검색 유입이 잘 안 붙더라고요. 제목이 두루뭉술하니까 검색 결과에서 클릭을 못 잡는 거예요. 같은 내용을 3편 시리즈로 쪼개서 올렸을 때 오히려 개별 글이 검색에 잘 잡혔고, 시리즈 간 내부 링크도 자연스럽게 이어졌어요.
자막 추출부터 전처리까지 유튜브 자막 블로그 자동화
유튜브 자막 블로그 자동화의 품질은 자막을 얼마나 깨끗하게 만드느냐에서 갈려요. 추출 자체보다 한국어 중복 문장을 먼저 줄이는 단계가 더 중요해요.
설마 자막 덩어리를 그대로 모델에 넣을 건 아니죠?
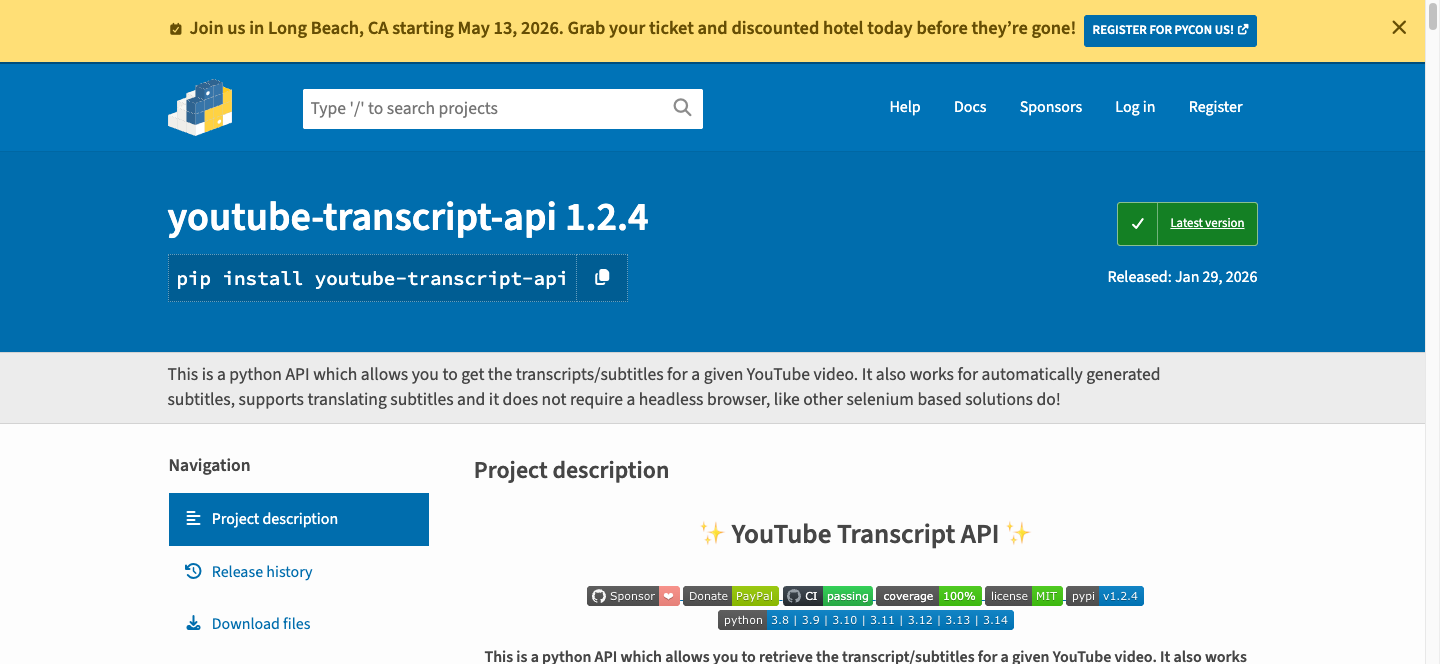
2026-04-13 기준 youtube-transcript-api는 PyPI 1.2.4이고 Python 3.8 이상에서 돌아가요. 직접 써보니 로컬에서는 5초 안에 자막이 쏟아지는데, 같은 코드를 EC2에 올리자마자 RequestBlocked가 떴어요. 공식 문서 기준으로 AWS, GCP, Azure 같은 클라우드 IP는 차단될 수 있거든요. 이 삽질 하나만 미리 알았으면 2시간은 아꼈을 거예요.
from youtube_transcript_api import YouTubeTranscriptApi
video_id = "VIDEO_ID"
transcript = YouTubeTranscriptApi().fetch(video_id, languages=["ko"])
for i, snippet in enumerate(transcript):
print(f"{snippet.start:.1f}s\t{snippet.text}")
if i == 2:
break
그다음은 한국어 중복 정리예요. kss는 한국어 문장 분리 라이브러리고, Jaccard 유사도는 두 문장이 얼마나 겹치는지 비율로 보는 방식이에요. 처음엔 정규식으로 문장을 잘랐는데, 한글에서 마침표 위치가 애매해서 문장이 이상하게 잘리더라고요. kss로 바꾸니까 훨씬 나았어요.
from kss import split_sentences
def jaccard(a: str, b: str) -> float:
a_set = set(a.replace(" ", ""))
b_set = set(b.replace(" ", ""))
if not a_set or not b_set:
return 0.0
return len(a_set & b_set) / len(a_set | b_set)
def dedupe_korean_transcript(text: str, threshold: float = 0.7) -> list[str]:
kept = []
for sentence in split_sentences(text):
sentence = sentence.strip()
if not sentence:
continue
if kept and jaccard(kept[-1], sentence) >= threshold:
continue
kept.append(sentence)
return kept
실전 흐름은 이렇게 잡으면 돼요.
# 1) 자막 받기
python pipeline/fetch_transcript.py --video-id VIDEO_ID --lang ko > data/transcript.txt
# 2) 중복 줄이기
python pipeline/clean_transcript.py data/transcript.txt > data/cleaned.txt
# 3) 시리즈 개요 만들기
python pipeline/make_series_outline.py data/cleaned.txt --parts 3 > draft/series-outline.md
예상 결과는 이래요.
transcript.txt에는 시간순 자막이 쌓인다cleaned.txt는 반복 문장이 빠져서 더 짧아진다series-outline.md에는 글 3편의 제목과 H2 뼈대가 생긴다
유튜브 블로그 변환에서 정리된 텍스트를 브리프로 넘기는 단계는 AI 브리프 워크플로우 쪽 흐름을 그대로 이어 붙이면 편해요.
Jaccard 임계값 0.7은 경험상 한국어 유튜브 자막에서 무난하게 동작해요. 0.6으로 낮추면 비슷하지만 다른 문장도 날아가고, 0.8로 올리면 미묘한 반복이 살아남아요. 처음엔 0.7로 시작하고, 결과를 보면서 한두 번 조정하면 충분해요.
클라우드에서 RequestBlocked가 뜨면 로컬에서 자막을 먼저 뽑아 파일로 저장하는 쪽이 빨라요. 굳이 서버에서 실시간으로 돌릴 필요가 없는 작업이거든요. 서버 파이프라인이 꼭 필요하면 Supadata API를 fallback으로 붙이면 되고요.
자막 텍스트를 블로그 구조로 바꾸는 프롬프트
정리된 자막은 그냥 요약시키면 안 돼요. 편수, 검색 의도, 필요한 예제, 사람이 채워야 할 칸까지 같이 넘겨야 블로그 뼈대가 살아나요.
유튜브 블로그 변환에서 같은 자막을 한 편짜리 요약글로 또 만들 이유가 있을까요?
프롬프트에서 제일 중요한 건 무엇을 빼야 하는지까지 적는 거예요. 자막 특유의 군더더기, 반복 호응, 진행 멘트는 빼고, 독자가 검색으로 들어왔을 때 바로 필요한 문제 해결 순서만 남겨야 하죠.
역할:
당신은 한국어 기술 블로그 편집자다.
입력:
정리된 유튜브 자막 1개
목표:
이 자막을 검색 의도별 블로그 시리즈 3편으로 나눈다.
규칙:
- 각 편은 서로 다른 질문 1개만 해결한다
- 각 편 제목에는 핵심 검색어를 자연스럽게 넣는다
- 각 편은 H2 3개, 체크리스트 1개, 실행 예제 1개를 포함한다
- 원본 영상에 없는 정보가 필요한 지점은 확인 태그를 남긴다
- 사실이 불분명하면 단정하지 않는다
출력:
1. 시리즈 제목 3개
2. 편별 독자 질문
3. 편별 H2 구조
4. 편별 CTA
5. 사람 검수 메모
프롬프트 출력은 아래 방향으로 가야 해요.
| 입력 상태 | 나쁜 출력 | 원하는 출력 |
|---|---|---|
| 시간순 자막 덩어리 | 요약문 1편 | 검색 의도별 시리즈 3편 |
| 반복 문장 다수 | 중복 문장 재서술 | 문제 -> 명령어 -> 검수 순서 |
| 진행 멘트 포함 | 말투만 매끈한 글 | 독자 행동이 보이는 구조 |
브리프를 먼저 만든 뒤 초안으로 넘기는 흐름이 익숙하다면 AI 블로그 브리프 만들기와 붙여서 써도 좋아요. 자막을 바로 글로 바꾸는 것보다, 자막 -> 브리프 -> 초안 2단으로 나누는 편이 실패가 적더라고요.
처음엔 자막 전체를 한 번에 넣고 “블로그 글로 바꿔줘”라고 했는데, 나온 결과가 자막 재서술이었어요. 시리즈 개요만 먼저 뽑고, 편별 초안은 따로 돌리는 2단계가 훨씬 안정적이더라고요. 유튜브 블로그 변환에서 프롬프트 설계가 차지하는 비중이 생각보다 커요.
구글에 안 밀리는 유튜브 콘텐츠 재활용 기준
2026년 3월 코어 업데이트는 2026-03-27에 시작해서 2026-04-08에 끝났어요. 이 시기 이후엔 자막을 매끈하게 다시 쓰는 것보다, 원본 영상에 없는 추가 가치가 있는지가 더 중요하다고 보는 쪽이 안전하죠.
자막만 매끈하게 고쳐서 올리면 될까요? 그것만으로는 부족해요.
구글 공식 문서는 March 2026 core update 공지와 helpful, reliable, people-first content 가이드에서 사람에게 먼저 도움이 되는 글을 계속 강조해요. 업계에선 이걸 흔히 “정보 이득”이라고 불러요. 공식 용어라기보다 원본에 없는 추가 가치 정도로 이해하면 맞아요.
발행 전에는 이 체크를 꼭 넣으세요.
- 원본 영상에 없던 명령어 순서를 추가해요
- 실패했을 때의 예외 상황을 적어두세요
- 비교표나 체크리스트가 있으면 붙이고요
- 직접 해본 흔적이 보이게 스크린샷도 넣어야 해요
- 마지막으로 사실과 표현은 사람이 다듬는 게 맞아요
| 추가할 것 | 왜 필요한가 |
|---|---|
| 명령어와 실행 순서 | 독자가 바로 따라 해볼 수 있다 |
| 실패 로그나 우회 방법 | 영상에 없는 실무 맥락이 생긴다 |
| 비교표 | 선택 기준이 빨라진다 |
| 스크린샷 | 신뢰가 붙는다 |
| 짧은 개인 의견 | 사람 냄새가 난다 |
구조화 데이터와 발행 화면까지 챙길 거면 워드프레스 SEO 설정: 설치 직후부터 스키마까지 한 번에 끝내기를 같이 보는 게 좋아요. 이 글은 변환까지, 그 글은 검색 노출 쪽 마감까지 잡아주죠.
Reddit r/SEO와 GeekNews에서도 자막만 다듬은 글이 검색에서 밀린다는 경험담이 꾸준히 올라오거든요. 원본에 없는 명령어 순서나 실패 사례를 추가하는 게 유튜브 블로그 변환의 품질을 결정짓는 핵심이에요.
전체 파이프라인 자동화에서 n8n과 CLI를 어떻게 나눌까
자동화는 한 덩어리로 묶지 말고, 터미널에서 돌릴 단계와 n8n으로 묶을 단계를 나눠야 덜 망가져요. 자막 추출과 전처리는 CLI가 편하고, 스케줄링과 알림은 n8n이 편하더라고요.
유튜브 블로그 변환 파이프라인을 처음부터 전부 노코드로만 가야 할 이유가 있을까요?
n8n은 공식 기준으로 Cloud, self-hosted, Embed 3가지 배포 형태가 있어요. Embed는 자기 서비스 안에 n8n 화면을 넣는 쪽이라 이 글에선 제외해도 돼요. 실무에선 Cloud냐 self-hosted냐만 보면 충분하죠.
중요한 건 예전 정보처럼 “커뮤니티 노드는 클라우드에서 전부 안 된다”라고 단정하면 틀릴 수 있다는 거예요. 공식 문서 기준으로 verified community node는 Cloud와 self-hosted 둘 다 설치 가능하고, 검증되지 않은 노드는 self-hosted 쪽에서 다루는 게 맞아요.
| 역할 | 도구 | 공식 기준 쓸 수 있는 환경 | 공식 시작 가격 | 언제 쓰면 맞나 |
|---|---|---|---|---|
| 자막 추출 | youtube-transcript-api |
Python 라이브러리, CLI | 무료 | 자막 있는 영상, 빠른 테스트 |
| 자막 대안 | Supadata | REST API, Python SDK, Node SDK, n8n/Make/Zapier/Active Pieces, MCP | Free 100 credits, Basic $5 | 자막이 없거나 서버형 처리 |
| 오케스트레이션 | n8n Cloud | Cloud 웹 | Starter 20유로/월(연간) | 세팅 빨리 끝내고 싶을 때 |
| 오케스트레이션 | n8n Community Edition | self-hosted 웹 | 무료 | 노드 자유도와 비용 절감이 우선일 때 |
| 올인원 SaaS | Castmagic (URL 넣으면 자막·요약·블로그 초안까지 한 번에 뽑아주는 구독형 서비스) | 웹 앱, API, URL import | Hobby $21/월(연간) | 바로 시작하고 싶지만 세부 제어는 덜 중요할 때 |
위 표 기준이면 추천은 이래요.
- 자막이 이미 있으면
youtube-transcript-api부터 쓴다 - 서버에서 막히거나 자막이 없으면 Supadata를 fallback으로 붙인다
- 파이프라인 연결은 n8n으로 하되, 전처리 스크립트는 CLI로 분리한다
- 초안이 나오면 워드프레스 자동 포스팅: REST API로 마크다운을 발행하는 파이프라인으로 발행 단계까지 넘긴다
참고로 MCP는 모델 컨텍스트 프로토콜, 즉 AI 도구에 문서나 API를 연결해주는 표준 정도로 보면 돼요. 이 글 주제에선 꼭 필요하진 않지만, 팀에 이미 AI 도구가 많다면 Supadata 쪽 확장성은 괜찮은 편이에요.
n8n Cloud 요금은 유로 기준이라 원화로 결제하면 환율에 따라 달라져요. Castmagic은 연간 결제 시 월 $21이고, 월간 결제는 더 비싸죠.
직접 써보니 유튜브 블로그 변환 파이프라인 전체를 돌리는 데 들어가는 도구 비용은 생각보다 작았어요. youtube-transcript-api가 무료이고, n8n도 Community Edition이면 서버 비용만 나오거든요. 구독형 올인원 도구는 편하지만, 세부 제어가 안 돼서 결국 CLI+n8n 조합으로 바꿨어요.
자주 묻는 질문
Q1. youtube-transcript-api가 서버에서 막히면 어떻게 하나요?
A: 직접 겪어봤는데, 공식 문서 기준으로 클라우드 IP에서 RequestBlocked나 IpBlocked가 날 수 있어요. 가장 쉬운 우회는 로컬에서 먼저 돌리는 거예요. 서버형이 꼭 필요하면 주거용 프록시나 Supadata 같은 API 대안을 붙이면 돼요.
Q2. 한국어 자막 중복은 그냥 모델이 알아서 정리하지 않나요?
A: 기대만큼 안 돼요. 같은 문장이 여러 번 들어가면 토큰만 더 먹고, 결과물도 말 돌리기처럼 나오기 쉽거든요. kss로 문장을 자르고, 문장 겹침 비율로 먼저 거르는 게 훨씬 나아요.
Q3. 자막 기반 글은 구글에서 중복 콘텐츠로 바로 찍히나요?
A: 대놓고 페널티라고 단정하긴 어려워요. 근데 자막 재서술만 한 글은 원본에 없는 가치가 약해서 경쟁력이 떨어지기 쉽죠. 명령어, 비교표, 실패 사례, 스크린샷을 붙여야 버텨요.
Q4. n8n Cloud에서 유튜브 자막 노드를 바로 쓸 수 있나요?
A: 노드 상태를 먼저 봐야 해요. 공식 문서 기준으로 검증된 커뮤니티 노드는 Cloud와 self-hosted 둘 다 설치할 수 있고, 검증되지 않은 노드는 self-hosted 쪽이 맞아요. 그러니 결제 전에 그 노드가 verified인지부터 체크하세요.
Q5. 완전 자동화까지 가도 되나요?
A: 유튜브 블로그 변환에서 초안 뼈대까진 자동으로 가도 돼요. 사실 체크, 스크린샷, 개인 의견까지 자동으로 넘기면 오히려 글이 비어 보일 확률이 크거든요. 자막 추출과 구조화는 자동, 최종 검수는 사람으로 나누는 게 현실적이에요.
다음 단계
관심 있는 영상 하나 골라서 자막부터 뽑아보세요. 직접 해보면 유튜브 블로그 변환이 생각보다 단순한 흐름이라는 걸 바로 느낄 수 있어요. 초안이 나오면 워드프레스 자동 포스팅: REST API로 마크다운을 발행하는 파이프라인으로 발행 단계까지 붙이면 돼요.