AI 에이전트 만들기: 도구 호출부터 워크플로우까지 실전 가이드
ai 에이전트 만들기 한 줄 요약
ai 에이전트 만들기의 핵심은 모델이 똑똑하냐보다,
도구 호출 → 결과 확인 → 다음 행동 결정루프를 내가 통제할 수 있느냐예요. Claude Agent SDK를 쓰면 이 루프를 짧게 시작할 수 있고, 대부분의 실무는 순차 워크플로우나 하이브리드 구조로도 충분하거든요. 처음부터 멀티 에이전트 시스템으로 가기보다, 워크플로우로 끝낼 일인지 먼저 가르는 게 비용도 덜 들고 덜 헤매요.
에이전트 프레임워크를 이것저것 붙여봤어요. 제일 늦게 남는 질문이 하나 있더라고요. ai 에이전트 만들기에서 뭘 먼저 잡아야 덜 삽질하느냐는 거죠. 코드 기준으로 정리해뒀어요.
처음엔 화면이 화려한 툴이 쉬워 보여요. 근데 실무에 넣으면 달라요. 파일을 읽고, 도구를 고르고, 실패하면 다시 판단하는 루프가 핵심이 되거든요. 구조를 못 잡으면? 데모는 돌아가는데 운영에 올리면 금방 꼬여요.
반대로 처음부터 멀티 에이전트 시스템으로 달리면? 토큰 비용이 먼저 튀죠. 역할이 흐트러져요. 사람도 왜 망가졌는지 못 읽게 되고요. 중간 지점을 잡는 데 초점을 맞췄어요.
워크플로우로 끝나는 일과 에이전트가 필요한 일을 먼저 나눠요. Anthropic Client SDK로 도구 호출 루프를 손으로 한 번 만들고, Claude Agent SDK로 같은 구조를 짧게 줄여볼게요. 마지막에 순차, 병렬, 평가자-최적화 패턴과 비용 가드레일까지 붙여둘게요.
에이전트는 워크플로우와 뭐가 다른가
워크플로우는 다음 단계가 미리 정해진 자동화예요. 에이전트는 모델이 상황을 보고 다음 행동을 고른다는 점이 다르죠.
이거 나만 헷갈린 건가 싶었는데, 여기서 한 번만 선을 그어두면 뒤가 훨씬 편해져요.
| 구분 | 워크플로우 | 에이전트 | 하이브리드 |
|---|---|---|---|
| 다음 단계 결정 | 코드가 정함 | 모델이 정함 | 뼈대는 코드, 일부만 모델이 정함 |
| 잘 맞는 일 | 포맷 변환, 예약 실행, 고정 승인 절차 | 탐색, 도구 선택, 예외 대응 | 대부분의 실무 자동화 |
| 장점 | 예측 가능, 싸게 굴리기 쉬움 | 유연함, 미지의 입력 대응 | 통제와 유연함 균형 |
| 실패 패턴 | 분기문이 폭증함 | 비용과 역할 표류가 빨리 옴 | 설계가 애매하면 둘 다 꼬임 |
| 추천 출발점 | 가장 먼저 | 정말 필요할 때 | 실무 기본값 |
실제로 직접 써보니까요. CSV 정리? 입력-출력이 고정돼 있어서 워크플로우 하나면 끝났어요. 근데 로그 분석은 달랐거든요. 파일 5개를 왔다갔다해야 했어요. 원인 판단까지 들어가니까 에이전트 구조가 필요하더라고요.
ai 에이전트 만들기를 고민 중이라면, 지금 자동화하려는 작업이 분기 3개 이하로 끝나는지부터 보세요. 끝나면 워크플로우. 아니면 에이전트를 고려할 타이밍이에요.
코드 없이 먼저 흐름부터 만져보고 싶으면 n8n 사용법: Docker 셀프호스팅부터 AI 워크플로우까지부터 보는 편이 빨라요. 시각화된 흐름에서 어디까지가 고정 로직이고, 어디부터 모델 판단이 들어가는지 눈에 잘 들어오거든요.
도구 호출 루프가 ai 에이전트 만들기의 핵심인 이유
ai 에이전트 만들기를 코드로 이해하려면? 도구 호출 루프부터 손에 익혀야 해요. 답만 쓰는 게 아니에요. 도구를 부르고, 결과를 읽고, 다시 판단하는 구조거든요.
설마 에이전트를 프롬프트 한 번 던지고 끝나는 챗봇 정도로 보고 있는 건 아니죠?
머릿속에 이 순서를 박아두세요.
- 모델에 도구 정의를 넘긴다
- 모델이
tool_use를 내면 애플리케이션이 그 도구를 실행한다 - 결과를
tool_result로 다시 모델에 넣는다 - 더 이상 도구 호출이 없으면 종료한다
import anthropic
client = anthropic.Anthropic()
tools = [
{
"name": "read_file",
"description": "작업 폴더 안의 텍스트 파일을 읽어요",
"input_schema": {
"type": "object",
"properties": {"path": {"type": "string"}},
"required": ["path"],
},
}
]
messages = [{"role": "user", "content": "README.md를 읽고 TODO를 요약해줘"}]
while True:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
tools=tools,
messages=messages,
)
messages.append({"role": "assistant", "content": response.content})
if response.stop_reason != "tool_use":
print(response.content.text)
break
for block in response.content:
if block.type != "tool_use":
continue
result = open(block.input["path"], "r", encoding="utf-8").read()
messages.append(
{
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": block.id,
"content": result,
}
],
}
)
실행하면 이런 흐름이 나와요.
# 1턴: 모델이 read_file 도구를 호출
tool_use: read_file(path="README.md")
# 2턴: 파일 내용을 받아서 다시 판단
tool_result: "# My Project\n- [ ] 테스트 추가\n- [ ] 배포 스크립트 작성..."
# 3턴: 도구 호출 없이 최종 답변
"TODO가 2개 있어요. 테스트 추가와 배포 스크립트 작성이에요."
장난감처럼 보여도 구조는 실전과 같아요. 파일 읽기를 웹 검색으로 바꿔도, DB 조회로 바꿔도 같은 루프예요.
외부 도구를 표준 방식으로 붙이는 모델 컨텍스트 프로토콜(MCP, Model Context Protocol)도 결국 이 흐름 위에 올라가요. MCP가 아직 낯설다면 MCP 서버 사용법: Claude Code 연결 가이드를 먼저 훑고 오세요. 금방 또렷해져요.
Claude Agent SDK로 첫 에이전트 만들기
Claude Agent SDK는 방금 본 도구 루프를 직접 짜는 대신, 권한과 세션까지 묶어둔 라이브러리예요. Python, TypeScript 둘 다 돼요. Bedrock, Vertex AI, Azure AI Foundry 인증도 공식 문서에 잡혀 있고요.
파일 읽기 권한, 세션 재사용, 비용 상한까지 매번 직접 분기문으로 만들고 싶은 건 아니죠?
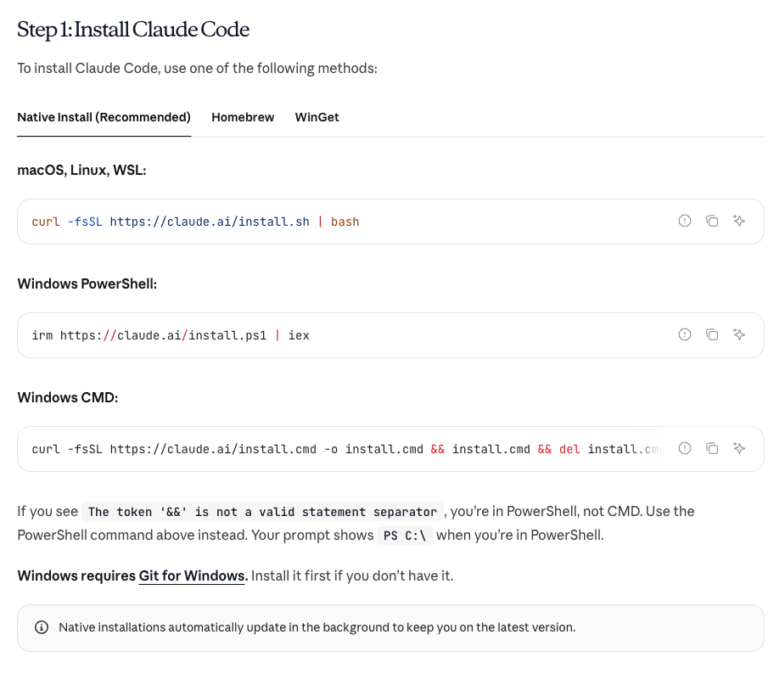
설치부터 짧게 가면 돼요.
# Python SDK 설치 (Python 3.10+)
pip install claude-agent-sdk
# API 키 세팅
export ANTHROPIC_API_KEY="your-api-key"
핵심 예제는 이 정도면 시작돼요.
import asyncio
from claude_agent_sdk import query, ClaudeAgentOptions
async def main():
async for message in query(
prompt="logs/app.log에서 500 에러 원인을 찾고 수정 방향을 요약해줘",
options=ClaudeAgentOptions(
allowed_tools=["Read", "Grep", "Bash"],
max_turns=6,
max_budget_usd=0.50,
),
):
print(message)
asyncio.run(main())
직접 돌려보면 터미널에 흐름이 쭉 찍혀요. Grep으로 에러 로그 찾고, Read로 코드 읽고, 수정 방향까지 잡아주거든요. max_turns=6이면 도구 6번 넘게 못 써요. max_budget_usd=0.50 넘으면 비용 초과로 멈추고요. 가드레일이 옵션 두 줄이에요.
여기서 눈여겨볼 건 세 가지예요.
| 항목 | Anthropic Client SDK | Claude Agent SDK |
|---|---|---|
| 도구 루프 | 직접 만든다 | 내장돼 있음 |
| 권한 제한 | 직접 짠다 | allowed_tools로 바로 건다 |
| 세션 재사용 | 직접 이어붙인다 | resume으로 이어간다 |
allowed_tools를 좁혀두면 불필요한 탐색이 줄어요. resume까지 붙이면? 이전 세션 맥락을 이어가니까 재탐색도 줄죠. Claude 계열 도구 흐름이 아직 낯설다면 Claude Code 사용법: 설치부터 첫 실행까지 5분 가이드부터 보고 오세요. 덜 헷갈릴걸요.
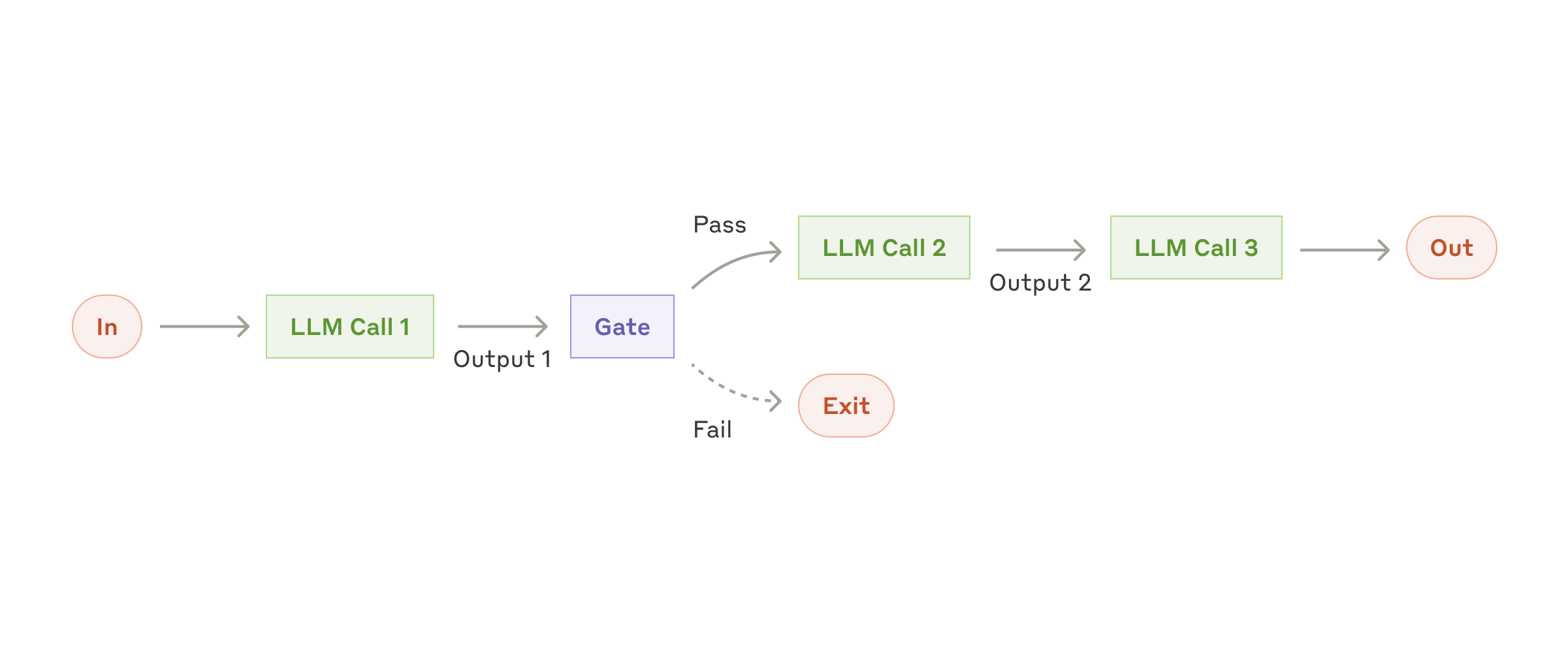
ai 에이전트 워크플로우 3패턴
ai 에이전트 워크플로우는 복잡해 보여도 순차, 병렬, 평가자-최적화 세 가지로 거의 정리돼요. 여기서 하나씩만 올려도 운영 난도가 꽤 달라져요.
설마 처음부터 에이전트 다섯 개 띄우고 서로 알아서 협업하길 기대하는 건 아니죠?
| 패턴 | 잘 맞는 작업 | 장점 | 위험 | 종료 조건 |
|---|---|---|---|---|
| 순차 | 리서치 → 요약 → 보고서 | 단순하고 읽기 쉬움 | 앞 단계 품질에 끌림 | 단계당 1회 |
| 병렬 | 여러 소스 동시 조사 | 속도가 잘 나옴 | 중복 읽기, 토큰 증가 | 결과 합치기 1회 |
| 평가자-최적화 | 초안 생성 후 품질 끌어올리기 | 결과 품질 안정화 | 무한 반복 | MAX_ITERATIONS 필수 |
평가자-최적화는 특히 종료 조건이 없으면 금방 비용이 새요. 핵심은 반복이 아니라, 반복을 언제 끊을지 미리 박아두는 거예요.
MAX_ITERATIONS = 4
draft = write_first_answer(topic)
for step in range(MAX_ITERATIONS):
score, feedback = critic(draft)
if score >= 8:
break
draft = revise(draft, feedback)
print(draft)
실제로 돌려보면 이런 흐름이에요.
# step 0: 초안 작성
# step 1: score 4.5 → feedback: "근거 부족, 코드 예시 없음" → 수정
# step 2: score 7.2 → feedback: "예시 추가됨, 결론 약함" → 수정
# step 3: score 8.3 → 기준 통과, 종료
3번 반복에 토큰은 대략 입력 3만 + 출력 1만 정도 썼어요. 종료 조건 없이 돌렸으면 4번째부터는 같은 피드백을 반복하면서 비용만 늘어났을 거예요.
브리프 생성이나 초안 교정 같은 작업은 이 패턴이 잘 맞아요. 리서치 초안 하나 뽑고, 품질 기준으로 다시 고친 뒤, 사람 검토에 넘기면 되거든요. 실제 콘텐츠 파이프라인에서 어떻게 쓰이는지 보고 싶다면 AI 블로그 브리프 자동 생성: 실전 파이프라인 구축기를 같이 보면 연결이 쉬워요.
멀티 에이전트 시스템 비용과 가드레일
멀티 에이전트 시스템은 성능보다 비용이 먼저 터져요. 데모는 돌아가요. 근데 운영에서 미끄러지는 이유? 종료 조건, 권한 범위, 사람 검토 지점이 비어 있어서죠.
토큰이 왜 이렇게 빨리 사라지나 싶을 때, 사실 에이전트가 똑똑해서가 아니라 쓸데없이 넓게 읽고 있어서인 경우가 많지 않나요?
직접 돌려본 경험인데요. “이 프로젝트 분석해줘”라고 던졌어요. 범위 없이. 토큰 18만 개 나왔거든요. 같은 작업을 “src/api/ 아래 에러 핸들링만 봐줘”로 좁혔더니? 5만 개면 끝나더라고요. 70% 가까이 줄어든 셈이죠.
아래 표는 2026년 4월 기준 공식 문서와 가격 페이지에서 확인한 주요 도구 비교예요.
| 도구 | 쓸 수 있는 환경 | 2026-04 공식 가격 메모 | 추천 상황 |
|---|---|---|---|
| Claude Agent SDK | Python SDK, TypeScript SDK, Claude API, Bedrock, Vertex AI, Azure AI Foundry | SDK 자체는 별도 라이선스 없음. Claude Sonnet 4.6 기준 입력 $3/백만 토큰, 출력 $15/백만 토큰 | Claude 생태계 중심, 도구 루프 자동화 |
| CrewAI | Python 패키지, CLI, 웹 콘솔, GitHub 연동 배포 | Basic Free, 50 workflow executions/월. Enterprise는 별도 문의 | 역할 기반 팀 구성을 빨리 만들 때 |
| LangGraph | Python, TypeScript, CLI, Studio Web UI, LangSmith 배포/관측 | LangGraph 오픈소스는 무료. LangSmith Developer 무료, Plus $39/seat | 상태, 분기, 인간 승인 제어를 세밀하게 잡을 때 |
| n8n | Cloud 웹앱, self-host 웹앱, REST API, CLI, AI Agent node | Community self-host 무료. Starter €20/월, Pro €50/월, Business €667/월 (연간 결제) | 코드 적게 쓰고 흐름부터 검증할 때 |
비용과 품질을 같이 잡는 체크리스트
아래 항목부터 붙이세요.
- 프롬프트 범위를 파일이나 디렉터리 수준까지 줄이기
allowed_tools같은 최소 권한 원칙 적용하기max_turns나MAX_ITERATIONS를 먼저 박아두기resume=session_id로 이전 세션을 이어서 재탐색 줄이기- 서브에이전트는 맥락 격리가 필요한 일에만 쓰기
- 모델 컨텍스트 프로토콜(MCP) 서버는 필요한 것만 켜기
- 사람 승인 단계 하나는 꼭 넣기
- 역할 표류(처음 맡긴 역할에서 벗어나는 현상)를 막으려면 성공 조건을 문장으로 고정하기
- 프로젝트 루트에
AGENTS.md같은 작업 규칙 파일을 두기
프롬프트를 길게 쓰는 것보다 성공 기준을 짧고 명확하게 적는 게 더 중요해요. 이 감각이 아직 애매하면 AI 프롬프트 엔지니어링: 블로거가 바로 쓸 수 있는 7가지 실전 기법을 같이 보는 편이 좋아요. 역할, 출력 형식, 종료 기준을 어떻게 고정하는지 바로 이어지거든요.
솔직히? 멀티 에이전트가 필요했던 적은 거의 없었어요. 하이브리드로 충분했거든요. 워크플로우 뼈대에 에이전트 한 단계만 끼우면 돼요.
멀티 에이전트를 진짜 고려한 건 서로 다른 코드베이스를 동시에 분석할 때뿐이었어요. 맥락이 완전히 분리돼야 하는 상황. 그게 아니면 복잡도만 올라가더라고요.
자주 묻는 질문
Q1: AI 에이전트와 LLM 워크플로우는 어떻게 다른가요?
A: LLM 워크플로우는 경로가 고정돼 있어요. 에이전트는 모델이 다음 행동을 고르죠. 실무에선 둘 중 하나만 쓰기보다, 워크플로우 뼈대 안에 에이전트 한 단계를 넣는 하이브리드가 제일 많이 남더라고요.
Q2: Claude Agent SDK와 Anthropic Client SDK는 언제 갈라서 써야 하나요?
A: 도구 호출 루프를 직접 통제하고 싶으면 Client SDK가 맞아요. 권한, 세션, 도구 실행, 훅까지 빨리 붙이고 싶으면 Claude Agent SDK가 낫고요. 처음엔 Agent SDK로 시작하고, 꼭 필요한 부분만 Client SDK로 내려가는 순서가 덜 아파요.
Q3: Claude Agent SDK는 Pro나 Max 같은 개인 구독으로도 되나요?
A: 2026년 4월 기준 공식 문서 흐름은 ANTHROPIC_API_KEY나 Bedrock, Vertex AI, Azure AI Foundry 자격증명을 전제로 해요. 개인 구독 로그인으로 붙이는 방식은 기본 경로가 아니라고 보면 돼요.
Q4: 멀티 에이전트 시스템에서 비용을 줄이려면 뭐부터 손봐야 하나요?
A: 범위부터 줄이세요. ai 에이전트 만들기에서 비용을 줄이는 첫 번째 방법은 파일명이나 작업 폴더를 먼저 지정하는 거예요. 도구 권한을 최소화하고, 세션을 재사용하면 체감 차이가 크거든요. MCP 서버를 이것저것 한꺼번에 로드하는 습관도 먼저 끊는 게 좋아요.
Q5: LangGraph, CrewAI, n8n, Claude Agent SDK 중 뭘 먼저 고르면 되나요?
A: 흐름 검증이 먼저면 n8n, 역할 기반 팀 구성이 먼저면 CrewAI, 상태와 분기 제어가 중요하면 LangGraph, Claude 생태계에서 도구 루프를 짧게 가져가고 싶으면 Claude Agent SDK가 편해요. ai 에이전트 만들기에서 처음부터 정답 하나 찾기보다, 지금 막히는 지점이 구조인지 운영인지부터 보세요.
다음 단계
바로 손을 움직일 거면 Claude Code 시작하기부터 열고, 외부 도구를 붙일 거면 MCP 서버 셋업로 넘어가세요. 코드 없이 흐름부터 검증하고 싶으면 n8n 사용법: Docker 셀프호스팅부터 AI 워크플로우까지부터 가는 편이 덜 헤매요.