GPT-5.5 vs Claude Opus 4.7: 터미널 작업과 코드베이스 리팩터링 어디에 쓸지
GPT-5.5 vs Claude Opus 4.7 한 줄 요약
결론부터. GPT-5.5 vs Claude Opus 4.7은 성능표 한 줄로 고르면 자꾸 빗나가요. 터미널에서 명령을 연쇄로 돌리고 끝까지 밀어붙이는 일은 GPT-5.5 쪽이 더 잘 맞고, 저장소 전체를 읽으면서 여러 파일을 묶어 고치는 리팩터링은 Claude Opus 4.7 쪽이 더 안정적으로 맞아떨어집니다. 2026-04-24 기준 공식 수치도 이렇게 갈려요. Terminal-Bench 2.0은 GPT-5.5가 82.7%, SWE-bench Pro는 Claude Opus 4.7이 64.3%였고, GPT-5.5는 아직 API가 열리지 않아 투입 경로까지 같이 봐야 해요.
최근 확인: 2026-04-24
Opus 4.7 청구서 보고 놀란 분들 많았을 거예요. 근데 2026년 4월 23일에 GPT-5.5가 붙으면서 비교가 더 헷갈려졌죠. 한쪽은 터미널에서 길게 맡길 때 시원하게 밀고, 다른 쪽은 코드베이스 전체를 읽고 구조를 바꾸는 데 강하거든요. 문제는 대부분 숫자만 던지고 끝난다는 점이에요. Terminal-Bench 2.0이 뭘 재는지, SWE-bench Pro가 실제 리팩터링과 얼마나 닿아 있는지 설명이 빠지면 실무에선 바로 못 써요. 저도 처음엔 “SWE-bench에서 앞서면 코딩도 다 이기겠지” 하고 봤다가, 정작 터미널 자동화 과제에선 다르게 느껴져서 기준을 다시 잡았어요. 여기선 GPT-5.5 vs Claude Opus 4.7을 터미널 자율 실행, 멀티파일 리팩터링, API 파이프라인 투입 가능 여부 세 갈래로 번역해둘게요. 읽고 나면 지금 맡은 작업을 어느 쪽에 보내야 할지, 둘을 섞어 쓸 때 어디서 갈라야 할지, 비용이 튀기 전에 뭘 먼저 체크해야 할지 바로 정할 수 있을 거예요.
GPT-5.5 vs Claude Opus 4.7 벤치마크를 어떻게 읽어야 하나
이 섹션은 숫자를 작업 종류로 번역해요. 표를 외우는 것보다, 어떤 벤치가 내 업무와 닮았는지 잡는 게 훨씬 중요하거든요.
SWE-bench에서 이겼다고 터미널도 다 먹는 걸까요?
그렇게 안 돼요. 같은 “코딩” 안에서도 자율 실행과 저장소 수정은 분리돼 있거든요. 공식 표는 OpenAI의 GPT-5.5 출시 페이지와 Anthropic의 Claude Opus 4.7 출시 페이지 기준으로 봤어요. 2026-04-16에 Claude Opus 4.7이 먼저 나왔고, 2026-04-23에 GPT-5.5가 붙었어요. 지금 시점에 제일 쓸모 있는 건 “누가 더 높냐”보다 “이 숫자가 무슨 일을 대신 보여주냐”입니다.
| 지표 | 뭘 재는지 | 실무에선 이렇게 읽으면 돼요 |
|---|---|---|
| Terminal-Bench 2.0 | 터미널에서 명령과 도구를 조합해 목표를 끝까지 끝내는지 | 긴 에이전틱 실행(명령 하나로 여러 턴에 걸쳐 스스로 도구를 호출하는 흐름), CLI 자동화, 로그 추적 |
| SWE-bench Pro | 실제 저장소에 패치를 만들고 검증까지 가는지 | 멀티파일 버그 수정, 리팩터링 품질 |
| GDPval | 문서와 분석 같은 지식 업무를 얼마나 정확히 푸는지 | 설계 메모, 조사, 의사결정 초안 |
| CursorBench | 편집기 안에서 큰 수정과 코드 품질을 얼마나 잘 다루는지 | IDE 중심 리팩터링, 코드베이스 이해 |
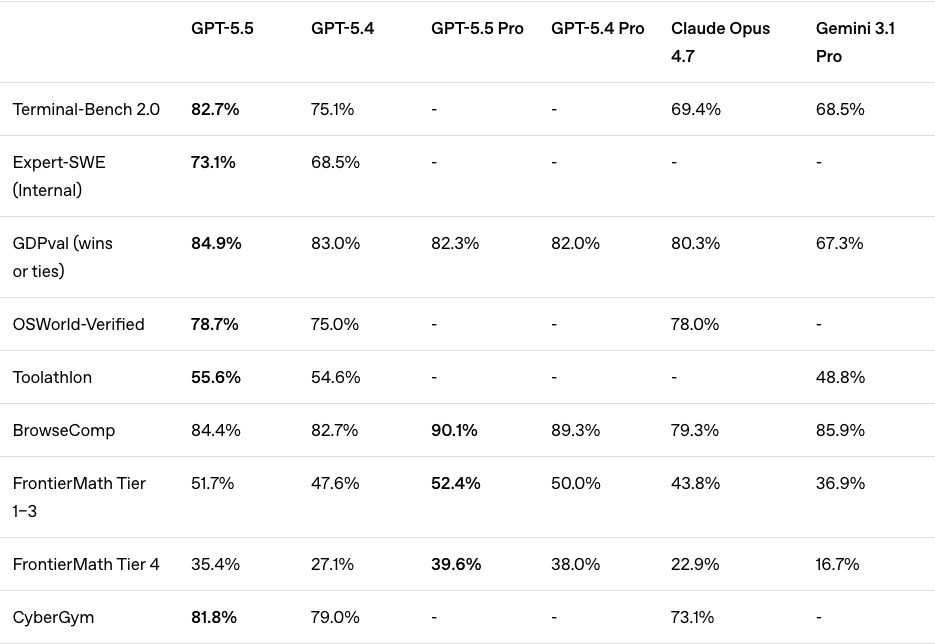
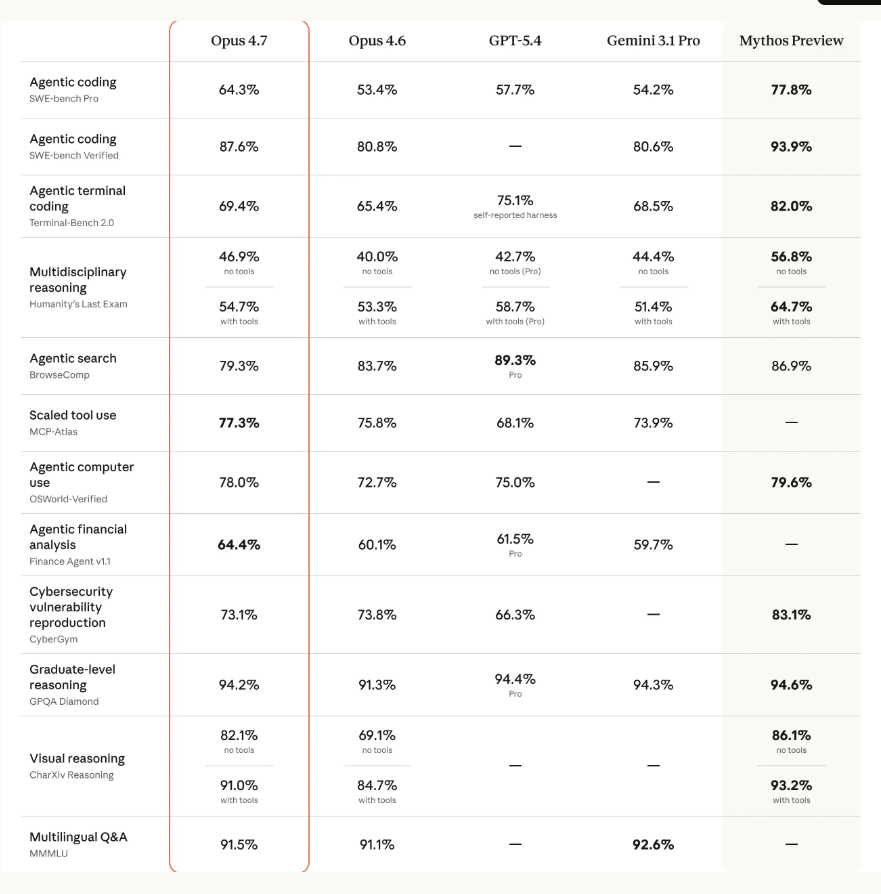
이 프레임으로 보면 갈림길이 꽤 또렷해져요. Terminal-Bench 2.0은 GPT-5.5가 82.7%로 앞서고, SWE-bench Pro는 Claude Opus 4.7이 64.3%로 앞서거든요. 같은 “코딩” 안에서도 자율 실행과 코드 품질이 분리돼 보인다는 뜻이죠. 비슷한 식으로 다른 모델 비교를 읽는 법은 Gemini 3 vs Claude Opus 4.7 코딩 비교: 실제 작업 5가지로 검증에도 그대로 이어집니다.
GPT-5.5가 앞서는 터미널 작업과 에이전틱 흐름
GPT-5.5는 터미널에서 오래 달리는 과제에 강해요. 명령을 조합하고, 중간 상태를 보고, 다음 액션을 정하는 흐름이 자연스럽게 이어질 때 힘이 납니다.
긴 작업을 맡길 때 매 단계마다 내가 붙들고 있어야 하면 그게 에이전트일까요?
OpenAI 공식 수치 기준으로 GPT-5.5는 Terminal-Bench 2.0에서 82.7%, GDPval에서 84.9%였어요. 같은 Terminal-Bench 2.0에서 Claude Opus 4.7은 69.4%라, 13.3%p 격차예요. 숫자만 보면 건조한데, 실제 체감은 “터미널에서 일감을 받아서 끝까지 밀어붙이는 타입”에 가깝습니다. 테스트 실패 3개 잡기, 린트와 타입 에러를 순서대로 정리하기, 로그와 웹 검색을 오가며 원인 좁히기 같은 일에서 잘 맞아요.
- 실패한 테스트, 린트, 포맷 정리를 한 세션에서 몰아서 끝내야 할 때
- 로그, 터미널 출력, 검색 결과를 오가며 원인을 좁혀야 할 때
- 결과보다 진행률과 중간 검증 루프가 더 중요한 작업일 때
# Codex로 터미널 작업을 맡기는 예시
codex exec "실패한 테스트를 찾아 고치고, 바뀐 파일과 남은 위험을 요약해줘"
# 출력 예시
작업 요약
- fixed: auth/session_test.py
- fixed: api/orders_test.py
- review-needed: flaky browser test 1건
정리하면, GPT-5.5는 “실행형”이에요. 설계를 길게 토론하기보다, 주어진 목표를 터미널에서 계속 밀어붙이는 쪽이 더 어울립니다. 도구 자체 차이를 먼저 보고 싶으면 Claude Code vs Codex: 직접 비교하고 정리한 선택 기준도 같이 보면 판단이 빨라져요.
Claude Opus 4.7이 앞서는 멀티파일 리팩터링
Claude Opus 4.7은 코드베이스를 읽고 관계를 정리하는 쪽이 더 강해요. 한 파일 고치기보다 여러 파일을 같이 건드리는 구조 수정에서 차이가 납니다.
레거시 폴더가 여러 겹인데 한 파일씩만 잘 고치면 끝날까요?
Anthropic 공식 발표 기준으로 Claude Opus 4.7은 SWE-bench Pro 64.3%, CursorBench 70%를 보여줬고, Claude Code 기본 추론 강도도 xhigh로 올라갔어요. 추론 강도는 모델이 답을 내기 전에 얼마나 오래 “생각”에 시간을 쓰는지 조절하는 단계예요. xhigh는 high와 max 사이 중간 지점이라, 어려운 코딩 과제에서 생각 시간을 조금 더 쓰되 max처럼 무겁게 가지 않는 타협점으로 보시면 됩니다.
- 타입, 인터페이스, 디렉터리 경계를 같이 손봐야 할 때
- “왜 이렇게 엮였는지” 먼저 읽고 설계 메모부터 뽑아야 할 때
- 리팩터링 뒤 테스트 통과보다 구조 일관성이 더 중요한 때
실제로 이런 타입의 일은 Claude Code 쪽이 훨씬 편하게 굴러가요. 터미널만 보는 게 아니라, VS Code, JetBrains, 데스크톱 앱, 웹 세션으로 넘겨가며 계속 볼 수 있거든요. 오래 읽고, 관계를 메모하고, 큰 수정안을 잡아두는 흐름이 잘 맞습니다. 저도 10~15파일이 엮인 구조 수정에서 xhigh로 돌렸을 때, 중간에 한 파일이 빠져도 다음 턴에 알아서 다시 집어오는 게 체감됐어요. GPT-5.5로 같은 일을 맡기면 테스트까지 끌어주는 대신, 초반 설계 묶음이 얕게 나오는 편입니다. xhigh를 어느 순간 켜야 하는지 더 자세히 보려면 Claude Opus 4.7 코딩 활용법: xhigh와 비전 업그레이드로 바뀐 실전 워크플로우를 이어서 보면 좋아요.
가격과 사용 환경에서 먼저 막히는 지점
이 섹션은 성능보다 먼저 걸리는 제약을 정리해요. 잘하는 일보다 “어디서 바로 쓸 수 있나”가 실제 선택을 더 빨리 갈라놓거든요.
성능표만 보고 골랐는데 내가 쓰는 환경에 안 들어가면 무슨 소용일까요?
2026-04-24 기준으로 GPT-5.5는 ChatGPT와 Codex에서 먼저 풀렸고, OpenAI API pricing page에는 coming soon으로 표시돼 있어요. 같은 날짜 기준 GPT-5.5 API 가격은 입력 $5, 캐시 입력 $0.50, 출력 $30 per 1M tokens로 공지됐습니다. Claude Opus 4.7은 같은 날짜에 Claude 웹, iOS, Android, desktop, Claude Code, Anthropic API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry까지 바로 들어가요. Anthropic 쪽 공식 가격은 입력 $5, 출력 $25 per 1M tokens예요.
| 항목 | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| 소비자 사용 환경 | ChatGPT 웹, iOS, Android, desktop | Claude 웹, iOS, Android, desktop |
| 코딩 전용 접점(surface) | Codex CLI, IDE extension, web, desktop app | Claude Code terminal, VS Code, JetBrains, desktop app, web |
| API / 클라우드 | API 미개방, 가격표만 먼저 공개 | Anthropic API, Bedrock, Vertex AI, Microsoft Foundry |
| 오늘 바로 막히는 점 | 팀 파이프라인에 당장 투입 불가 | 체감 비용 감시 필요 |
커뮤니티에서 갈린 두 가지 불만
커뮤니티 반응도 여기서 갈렸어요. GPT-5.5는 “잘 도는데 API가 아직 없다”가 불만이고, Opus 4.7은 “잘 푸는 과제가 있는데 청구서가 먼저 티 난다”는 반응이 많더라고요. Anthropic 공식 발표가 직접 짚은 대로, Opus 4.7은 가격표($5/$25)는 그대로지만 토크나이저가 바뀌어 같은 입력도 이전보다 더 많은 토큰으로 잡힙니다. 체감 청구서가 커 보이는 이유예요. xhigh를 올릴수록 더 심해질 수 있으니, 비용 감시를 같이 붙이는 게 안전합니다. 추론 강도별 사용 패턴은 Claude Code thinking 모드: low/medium/high/xhigh 언제 쓰는지도 같이 보면 기준이 또렷해집니다.
실제 워크플로우: 설계는 Claude 실행은 GPT-5.5
이 섹션은 둘을 같이 쓰는 가장 실용적인 흐름을 보여줘요. 하나만 고집하기보다, 설계와 실행을 나누면 오히려 덜 헤맵니다.
둘 중 하나만 고집해야 할 이유가 있나 싶지 않나요?
아래처럼 나누면 깔끔해요. 구조와 위험 목록은 Claude Opus 4.7이 먼저 잡고, 실제 수정과 검증 루프는 GPT-5.5가 맡는 방식입니다.
- 설계안 먼저 받기
# Claude Code로 리팩터링 계획 초안 만들기
claude -p "payments 모듈을 읽고 리팩터링 계획을 체크리스트로 정리해줘" > refactor-plan.md
# 예상 산출물
# - 변경 대상 파일 목록
# - 위험 포인트
# - 테스트 순서
- 실행은 Codex로 넘기기
# Codex로 실제 수정과 테스트 맡기기
codex exec "refactor-plan.md를 읽고 수정한 뒤 테스트를 돌리고 결과를 요약해줘"
# 출력 예시
작업 요약
- changed files: 12
- tests passed: 31
- manual review: payment timeout 경계값
-
마지막은 사람이 확인하기
-
공개 API 시그니처가 바뀌지 않았는지 보기
- 로그와 에러 메시지가 더 헷갈리게 바뀌지 않았는지 체크
- 남은 TODO가 진짜 발행 가능한 수준인지 판단하기
이 패턴은 특히 “리팩터링 설계는 꼼꼼해야 하는데, 실제 검증은 터미널에서 오래 돌려야 하는” 팀에 잘 맞아요. 저도 한 주 이렇게 나눠 돌려보니, 설계 단계에서 Claude Opus 4.7이 잡아주는 체크리스트가 Codex 쪽 실행 속도와 시너지가 났어요. 한 모델만 쓸 때보다 중간에 “이 파일은 왜 바꿨지”를 되짚는 일이 줄었습니다. 클라우드 세션까지 길게 끌고 가는 식으로 확장하려면 Claude Code Ultraplan으로 클라우드에서 대규모 리팩터링 돌리기를 같이 보면 바로 응용할 수 있습니다.
자주 묻는 질문
Q1: SWE-bench에서 Claude가 앞서면 실제 코딩도 Claude가 더 나은 건가요?
A: 꼭 그렇진 않아요. SWE-bench Pro는 저장소 패치와 검증에 더 가깝고, 터미널 자동화는 Terminal-Bench 2.0 쪽이 더 닮아 있어요. 리팩터링이면 Claude Opus 4.7, 자율 실행이면 GPT-5.5로 먼저 생각하면 덜 틀립니다.
Q2: GPT-5.5 API는 지금 바로 쓸 수 있나요?
A: 2026-04-24 기준으로는 아니에요. ChatGPT와 Codex에 먼저 풀렸고, OpenAI pricing page에는 coming soon으로 올라와 있습니다. API 파이프라인을 당장 돌려야 하면 당분간 기존 API 모델을 유지하는 편이 현실적이에요.
Q3: Opus 4.7이 유독 토큰을 많이 먹는 느낌은 왜 드나요?
A: 공식 API 가격표는 단순한데, 체감 비용은 긴 프롬프트와 큰 코드베이스에서 더 세게 느껴질 수 있어요. 한 번에 전체 리팩터링을 던지기보다 파일 단위 체크포인트로 쪼개는 쪽이 안전합니다.
Q4: 복잡한 멀티파일 리팩터링은 뭘 먼저 쓰면 좋나요?
A: Claude Opus 4.7부터 시작하는 편이 낫습니다. 구조를 읽고, 바꿀 범위를 정하고, 테스트 순서를 먼저 잡아두면 이후 실행이 한결 수월해져요. 그다음 터미널 검증과 반복 실행은 GPT-5.5로 넘기는 식이 실용적입니다.
Q5: 둘 다 쓸 거면 순서를 어떻게 잡아야 하나요?
A: 설계와 위험 목록은 Claude Opus 4.7, 실제 수정과 장시간 검증은 GPT-5.5로 두세요. 마지막 diff와 커밋 전 확인은 사람이 해야 합니다. 이 순서가 제일 덜 피곤해요.
다음 단계
이번 주 과제 5개만 뽑아서 터미널 자율 실행과 멀티파일 리팩터링으로 먼저 나눠보세요. 이어서 Claude Opus 4.7 코딩 활용법: xhigh와 비전 업그레이드로 바뀐 실전 워크플로우와 Claude Code Ultraplan으로 클라우드에서 대규모 리팩터링 돌리기까지 붙여 보면 팀용 라우팅 규칙이 금방 잡힐 거예요. 갈림길이 다르게 나왔다면 댓글로 케이스 남겨주세요.