Claude Code Monitor 도구로 배포 로그 실시간 추적하기
claude code monitor 한 줄 요약
claude code monitor는 사실 두 개예요. 하나는 2026-04-09 주간 릴리스에서 들어온 Claude Code built-in Monitor tool로, 백그라운드 명령 결과가 나올 때만 Claude를 깨워서 폴링 낭비를 줄여줘요. 다른 하나는/stats,ccusage,claude-monitor, OpenTelemetry 같은 사용량 모니터 흐름이라서, 5시간 한도와 토큰·비용을 숫자로 보고 싶다면 이쪽을 켜야 해요. 로그 감시는grep --line-buffered, 실패 감지는2>&1, 구독 사용량 체크는/stats나npx ccusage@latest blocks부터 시작하면 돼요.
Pro $20 쓰는데 오후만 되면 갑자기 흐름이 끊기던 날이 있었어요. 경고는 뜨는데, 지금 얼마나 썼는지 바로 안 보여서 터미널 하나 더 열고 이것저것 뒤지게 되더라고요. 문제는 검색어부터 헷갈린다는 점이에요. claude code monitor를 치면 Anthropic이 넣은 built-in Monitor tool 얘기와 ccusage, Claude Code Usage Monitor 같은 사용량 도구 얘기가 한꺼번에 섞이거든요. 그래서 로그 감시를 찾다가 비용 화면만 보고 나오거나, 반대로 5시간 한도를 보고 싶은데 stdout 이벤트 설명만 읽고 끝나는 일이 생겨요. 2026-04-18 기준으로는 공식 quick glance도 생겼어요. 구독자는 /stats로 usage pattern을 보고, API 사용자는 /cost로 세션 토큰 비용을 볼 수 있죠. 근데 여기서도 끝이 아니에요. 실시간 경고, 상태줄, 5시간 블록 뷰는 아직 커뮤니티 도구가 더 촘촘하더라고요. 그래서 이 글은 이름부터 둘로 자르고, 그다음 grep --line-buffered를 왜 꼭 붙여야 하는지, stderr가 왜 조용히 빠지는지, 어떤 도구를 어디까지 쓰면 좋은지 실전 순서로 묶었어요. Claude Code 자체가 처음이면 Claude Code 사용법: 설치부터 첫 실행까지 5분 가이드도 같이 열어두면 덜 헤맬 거예요.
Claude Code Monitor가 가리키는 두 가지
이 섹션은 같은 검색어에 섞여 들어온 두 대상을 먼저 갈라놓는 곳이에요. 여기만 정리되면 뒤에서 명령어를 봐도 덜 꼬여요.
같은 단어로 찾았는데 물건이 둘이면, 처음부터 갈라야 하지 않겠어요?
Claude Code 주간 릴리스 노트와 Tools reference, 그리고 커뮤니티 도구 문서를 같이 보면 구조가 명확해져요.
| 구분 | built-in Monitor tool | usage monitor |
|---|---|---|
| 핵심 목적 | 이벤트가 생길 때만 Claude를 깨우기 | 토큰, 비용, 5시간 한도, 세션 패턴 보기 |
| 공식 여부 | Anthropic 공식 | 커뮤니티 도구 또는 OpenTelemetry 스택 |
| 주 사용 환경 | Claude Code 로컬 세션 중심. CLI, VS Code 확장, JetBrains 플러그인에 붙은 세션에서 쓰기 좋음 | 터미널 CLI, 상태줄, MCP(Model Context Protocol, 외부 도구 연결 규약) 서버, 웹 대시보드 |
| 대표 시작점 | 로그 tail, PR 상태 감시, 파일 변화 감시 | /stats, npx ccusage@latest blocks, claude-monitor, OTel 대시보드 |
| 잘 맞는 상황 | 폴링 줄이기, 배포 로그 감시, CI(continuous integration, 자동 빌드·테스트 파이프라인) 상태 반응 | “지금 얼마 썼지?” “언제 한도 풀리지?” 보기 |
| 놓치기 쉬운 함정 | stdout만 이벤트예요. stderr는 따로 처리해야 해요 | 숫자는 보여도 자동 반응은 안 해줘요 |
참고로 Claude Code 자체는 공식 platforms 문서 기준으로 CLI, 데스크톱 앱, VS Code 확장, JetBrains 플러그인, 웹, 모바일 모니터링, Chrome 확장, Slack 앱, GitHub Actions·GitLab CI/CD 연동까지 넓게 퍼져 있어요. 근데 오늘 말하는 built-in Monitor tool은 그중 로컬 Claude Code 세션 안에서 쓰는 built-in tool이고, usage monitor는 그 바깥에서 붙는 보조 도구인 셈이죠. 기본 설치 흐름이 아직 낯설면 Claude Code 사용법를 먼저 보고 오는 편이 빨라요.
claude code monitor tool로 폴링 끊기
이 섹션은 built-in Monitor tool을 어디에 붙이면 토큰 낭비를 줄일 수 있는지 보여줘요. 끝날 때까지 주기적으로 다시 묻는 루프를 끊는 게 핵심이에요.
10분짜리 작업에 30초마다 다시 물어보면, 대부분은 빈손인데 그걸 계속 할 이유가 있을까요?
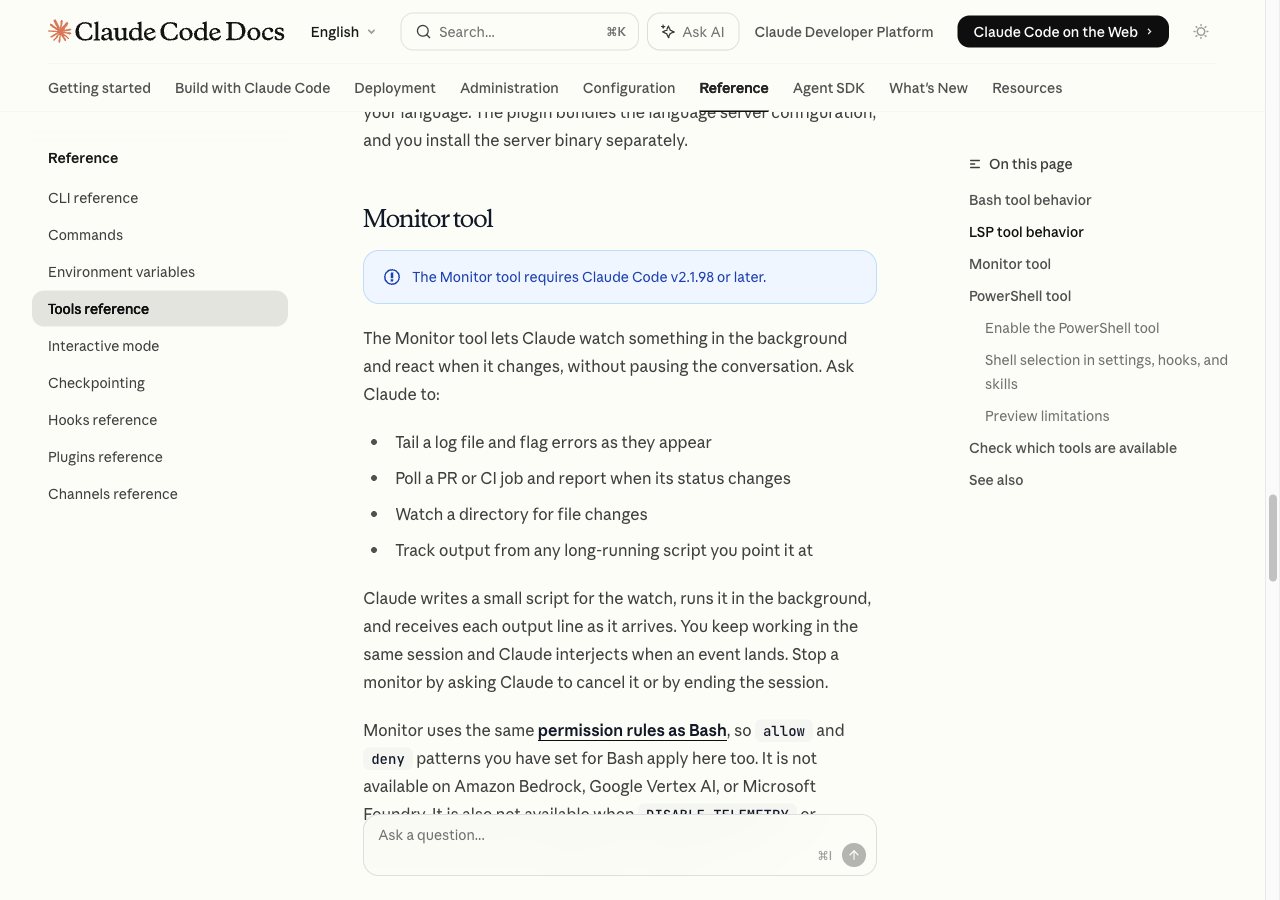
공식 릴리스 노트 기준으로 Monitor tool은 Claude Code v2.1.98부터 들어왔고, /loop도 같은 주에 self-pacing 쪽으로 바뀌었어요. 즉 “시간 되면 다시 물어봐”보다 “이벤트가 뜨면 깨워줘”가 이제 기본 방향이에요.
# 예전 폴링 습관
while true; do
curl -fsS http://localhost:8080/health || true
sleep 30
done
# 이벤트만 흘려보내는 쪽
kubectl logs -f deploy/api \
| grep --line-buffered -E "ERROR|FATAL|CrashLoopBackOff"
이걸 Claude에게 붙일 때는 툴 스키마를 외울 필요 없어요. 보통은 이렇게 말하면 충분해요.
배포 로그를 background monitor로 보고, ERROR나 FATAL이 뜨면 바로 알려줘.
실전에서는 아래 세 가지만 챙기면 돼요.
- stdout, 그러니까 표준 출력으로 한 줄씩 흘러나오게 만든다
- 성공 신호만 말고 실패 패턴도 같이 잡는다
- 오래 보는 로그 tail이나 PR 감시는 세션 길게 유지하는 쪽으로 잡는다
배포 확인이나 PR 자동 감시처럼 “기다리는 시간”이 긴 흐름은 Claude Code 루틴 실전 가이드: PR 리뷰·배포 검증을 노트북 꺼도 돌리는 법과도 잘 붙어요. built-in Monitor tool은 여기서 진가가 나더라고요.
grep –line-buffered와 stderr 함정 피하기
이 섹션은 built-in Monitor tool을 써도 왜 알림이 늦거나, 아예 안 오는지 정리해요. 실수는 단순한데 체감 손해가 꽤 커요.
에러가 났는데 채팅이 조용하면, 성공인지 실패인지 어떻게 구분할까요?
GNU grep 공식 매뉴얼은 --line-buffered가 표준 출력 버퍼를 줄 단위로 flush한다고 적고 있어요. 커뮤니티가 추적한 Monitor tool 설명도 이 옵션을 강하게 권하죠. 여기서 삐끗하면 이벤트가 몇 분씩 밀릴 수 있어요.
# 늦게 오는 패턴
tail -f app.log | grep "ERROR"
# 바로 오는 패턴
tail -f app.log | grep --line-buffered "ERROR"
stderr, 그러니까 표준 에러도 함정이에요. Monitor 쪽 이벤트는 stdout 기준으로 들어오는데, 프로세스가 stderr로만 죽으면 채팅은 조용할 수 있거든요.
# READY만 잡는 패턴 - 실패가 조용히 빠질 수 있어요
./watch-app | grep --line-buffered "READY"
# 실패도 같이 보이게 합치기
./watch-app 2>&1 | grep --line-buffered -E "READY|ERROR|FATAL|Traceback"
한 번에 정리하면 이래요.
| 함정 | 왜 문제인가 | 바로 고치는 법 |
|---|---|---|
grep 기본 버퍼링 |
줄이 모일 때까지 늦게 보낼 수 있어요 | --line-buffered 추가 |
| stderr 전용 크래시 | Monitor 알림이 조용할 수 있어요 | 2>&1로 stdout에 합치기 |
| 성공 패턴만 감시 | 실패나 hang가 침묵처럼 보여요 | 실패 패턴도 같이 넣기 |
이걸 훅이나 상태줄 알림으로 더 다듬고 싶다면 Claude Code Hooks 완벽 가이드 – 자동화 훅 설정법도 바로 이어져요. 로그 감시는 반응 속도, 상태줄은 시야 확보. 역할이 다르거든요.
claude code 사용량은 어디서 보나
이 섹션은 “지금 얼마나 썼나”를 어디서 확인해야 하는지 정리해요. 구독자와 API 사용자는 보는 창이 다르거든요.
한도 경고가 뜬 다음에 숫자 보는 건 이미 늦은 거 아닌가요?
Manage costs effectively 문서를 보면 공식 기준은 이렇게 갈려요. API 사용자는 /cost가 맞고, Pro·Max 같은 구독자는 /stats로 usage pattern을 봐요. 실시간 5시간 블록이나 상태줄 경고는 아직 ccusage나 claude-monitor가 더 실용적인 편이고요. Claude pricing과 Claude Help Center 요금 가이드 기준 2026-04-18 현재 개인 요금은 Pro $20/월($200/년), Max 5x $100/월, Max 20x $200/월이에요. 중요한 점 하나. Anthropic 공식 도움말 센터(Help Center) 안내대로 Claude 앱과 Claude Code 활동은 같은 구독 한도를 같이 써요.
# 구독자라면 먼저 보기
/stats
# API 토큰 비용이 궁금하면
/cost
# 5시간 블록을 숫자로 보기
npx ccusage@latest blocks
# 상태줄에 붙일 1줄 출력
npx ccusage@latest statusline
# 좁은 터미널이나 캡처용
npx ccusage@latest blocks --compact
# 터미널 대시보드
uv tool install claude-monitor
claude-monitor
도구별 차이는 이 정도로 보면 돼요.
| 보는 도구 | 공식 여부 | 쓸 수 있는 환경 | 뭘 보여주나 | 추천 대상 |
|---|---|---|---|---|
/stats |
공식 | Claude Code 세션 | daily usage, session history, streaks, model preferences | 구독자 quick glance |
/cost |
공식 | Claude Code 세션, API billing | 현재 세션 토큰 비용 | API 사용자 |
ccusage |
커뮤니티 | CLI, docs 사이트, MCP 서버 | 5시간 블록, 모델별 비용, 상태줄 | 개인, 파워유저 |
claude-monitor |
커뮤니티 | 터미널 대시보드 CLI | 실시간 사용량, 비용, 경고 UI | 숫자를 상시 보고 싶은 개인 |
세션이 자꾸 둘셋으로 늘어나는 구조라면 Claude Code 서브에이전트 만들기 실전 가이드: 자동 위임·비용 절감 세팅까지도 같이 보는 게 좋아요. 구조를 안 바꾸면 요금만 올려도 같은 데서 또 막히거든요.
ccusage, claude-monitor, OTel 중 뭘 고르나
여기선 개인용 CLI, 터미널 대시보드, 팀용 관측 스택을 고르는 기준만 자를게요. 기준은 예쁜 UI가 아니라 누가 볼지와 어디로 보낼지예요.
혼자 쓰는데 Grafana(대시보드 도구)까지 올리는 건 좀 과하지 않나요?
혼자면 ccusage나 claude-monitor에서 끝나는 경우가 많아요. 팀이면 Monitoring 문서대로 OpenTelemetry, 줄여서 OTel(관측 데이터 표준) export를 켜고, 거기서 Grafana 웹 대시보드나 다른 백엔드로 보내는 쪽이 오래 가요. claude-code-otel은 그 흐름을 빠르게 띄우는 오픈소스 스택이고, SigNoz는 Cloud와 self-hosted 둘 다 있는 OTel 기반 서비스, Datadog는 제품별 과금이 붙는 관측 SaaS예요.
| 옵션 | 주 사용 환경 | 설치·운영 감각 | 잘 맞는 규모 | 장점 | 주의 |
|---|---|---|---|---|---|
ccusage |
CLI + MCP 서버 | 제일 가벼움 | 1인 | 무설치 npx, 5시간 블록, 상태줄 |
자동 알림은 직접 엮어야 해요 |
claude-monitor |
터미널 대시보드 CLI | 가벼움 | 1인~소규모 | 실시간 화면이 직관적 | 터미널을 계속 열어두는 편이 좋아요 |
claude-code-otel + Grafana |
웹 대시보드 | 중간 | 2인~5인 | 사용자·모델·도구별 지표 보기 좋음 | 수집기와 대시보드 운영이 필요해요 |
| SigNoz | Cloud 또는 self-hosted 웹 | 중간 | OTel 이미 쓰는 팀 | 로그·메트릭·트레이스 한곳에 모으기 쉬움 | 백엔드 운영 또는 usage-based 과금 구조를 봐야 해요 |
| Datadog | 웹 SaaS | 쉬움 | 이미 Datadog 쓰는 팀 | 알림, 대시보드, 연동이 강해요 | 제품별 과금이라 비용 구조가 빨리 커질 수 있어요 |
공식 quick start는 이 환경 변수부터예요.
# Claude Code OTel 내보내기 켜기
export CLAUDE_CODE_ENABLE_TELEMETRY=1
export OTEL_METRICS_EXPORTER=otlp
export OTEL_LOGS_EXPORTER=otlp
export OTEL_EXPORTER_OTLP_PROTOCOL=grpc
export OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:4317
# Claude Code 실행
claude
혼자 쓰는데도 Opus 쪽이 자꾸 먼저 한도를 먹는다면, 플랜 점프부터 하지 말고 모델 분배부터 보는 게 나아요. 그 기준은 Claude Haiku 4.5로 비용 1/5 코딩: Opus 대신 써야 할 때는 언제?와 같이 보면 금방 정리돼요.
자주 묻는 질문
Q1. Claude Code Monitor tool이랑 usage monitor는 같은 건가요?
A: 아니에요. built-in Monitor tool은 이벤트가 생길 때 Claude를 깨우는 공식 기능이고, usage monitor는 토큰·비용·5시간 한도를 보는 보조 도구예요. 같은 검색어로 묶여 보여서 처음에 제일 많이 헷갈려요.
Q2. tail -f ... | grep "ERROR"만 썼는데 왜 알림이 늦게 와요?
A: grep 기본 출력이 줄마다 flush되지 않을 수 있어서 그래요. GNU grep 공식 매뉴얼 기준으로 --line-buffered를 붙이면 줄 단위로 바로 흘러가요.
Q3. 공식 사용량 화면은 없나요?
A: 있어도 역할이 좀 달라요. 구독자는 /stats로 usage pattern을 보고, API 사용자는 /cost로 세션 토큰 비용을 봐요. 5시간 블록이나 상태줄 경고까지 보려면 ccusage나 claude-monitor가 아직 더 촘촘해요.
Q4. Claude 앱이랑 Claude Code가 한도 따로 쓰나요?
A: 아니요. Anthropic 공식 도움말 센터(Help Center) 안내대로 Pro·Max 사용량은 Claude와 Claude Code가 같이 써요. 웹에서 길게 쓰고 바로 Claude Code를 열면 생각보다 빨리 경고가 뜨는 이유가 여기 있어요.
Q5. Bedrock이나 Vertex AI에서도 built-in Monitor tool을 쓸 수 있나요?
A: 공식 Tools reference는 built-in Monitor tool이 Amazon Bedrock, Google Vertex AI, Microsoft Foundry에서는 없다고 적고 있어요. 그 환경이면 usage monitor나 OTel 쪽으로 먼저 가는 편이 맞아요.