gemini 3 vs claude 코딩 한 줄 요약
짧은 답: 멀티파일 리팩토링, 버그 디버깅, 테스트 자동 생성처럼 여러 단계를 스스로 이어야 하는 일은 Claude Opus 4.7이 더 안정적인 쪽에 가까워요. 반대로 대형 코드베이스를 훑고 구조를 빠르게 읽거나, 비용을 아끼면서 먼저 탐색할 때는 Gemini 3.1 Pro가 부담이 덜하죠. 다만 2026년 4월 18일 기준으로 Opus 4.7은 정식 공개 모델이고 Gemini 3.1 Pro는 아직 정식 출시 전 버전이라, 이 전제를 빼고 붙이면 비교가 살짝 비뚤어져요.
벤치마크 표만 보고 모델 고르면 꼭 한 번은 다시 결제하게 되더라고요. gemini 3 vs claude 코딩 비교도 딱 그랬어요. 표에선 비슷해 보여도, 실제로 붙이면 파일 세 개를 같이 건드리는 순간, 실패한 테스트를 끝까지 다시 돌리는 순간, 처음 보는 모노레포를 얼마나 빨리 읽느냐에서 결이 꽤 갈리거든요. 저도 처음엔 무료 진입이 되는 Gemini CLI 쪽이 더 끌렸어요. 근데 리팩토링과 디버깅처럼 여러 단계를 이어 가는 일은 Claude 쪽이 더 안정적으로 마감해 줬고, 구조 훑기와 빠른 탐색은 Gemini 쪽이 생각보다 편했어요. 돈 얘기도 빼놓기 어려워요. 월 구독료는 비슷해 보여도 API 가격과 긴 문맥창 과금까지 들어오면 셈법이 바로 바뀌죠. 그래서 이번 글은 말빨 말고 작업 5개로 자를 거예요. 비교 대상이 정확히 뭔지 먼저 맞추고, 같은 조건으로 실행한 뒤, 리팩토링·디버깅·테스트 생성·대형 코드베이스 탐색·신규 기능 구현을 순서대로 살펴볼게요. 마지막엔 둘 중 하나만 고르는 대신, 어떤 구간을 Gemini에 넘기고 어떤 구간을 Claude로 마감하면 좋은지도 바로 써먹게 정리할게요. Claude 쪽 배경을 먼저 잡고 싶으면 Claude Opus 4.7 코딩 활용법: xhigh와 비전 업그레이드로 바뀐 실전 워크플로우를 같이 열어두세요. 왜 결과가 갈리는지 읽기가 훨씬 쉬워져요.
2026년 4월 기준, 비교 대상부터 맞춰야 해요
gemini 3 vs claude 코딩 비교는 모델 이름 하나만 보는 글이 아니고, 실제로 어디서 어떻게 쓰는지까지 맞춰야 의미가 있어요. 2026년 4월 18일 기준으로 Opus 4.7은 정식 공개 모델이고, Gemini 3.1 Pro는 아직 정식 출시 전 버전이라 이 전제부터 못 박고 가야 해요.
같은 이름만 보고 붙이면 비교가 되겠어요?
이름부터 정리해야 문장이 꼬이지 않아요
편의상 이 글에선 그냥 Gemini 3라고 쓰지만, 실제로 돌린 모델은 Gemini 3.1 Pro예요. 3 Flash, 3.1 Flash-Lite, 3 Pro Image까지 갈래가 여러 개라, 이름만 ‘Gemini 3’로 부르면 어떤 모델을 쓴 건지 금방 헷갈리거든요. Claude 쪽도 갈래가 많은 건 똑같아요. 웹앱의 Claude, 터미널의 Claude Code, 브라우저 확장인 Claude for Chrome, API로 붙는 Claude Platform까지 제품 이름과 사용 환경이 조금씩 달라요. 이 글은 터미널 도구인 Claude Code를 기준선으로 잡고, 브라우저 쪽 흐름이 궁금하면 Claude Code on the Web 사용법: 브라우저에서 돌리는 AI 코딩 에이전트를 같이 열어두세요.
어디서 실제로 쓸 수 있는지 먼저 본다
| 사용 환경 | Claude 쪽 | Gemini 쪽 | 이 글에서 다루는 정도 |
|---|---|---|---|
| 웹앱 | claude.ai |
gemini.google.com |
비교 전 성격 정리만 |
| 모바일 앱 | iOS, Android 앱 | iOS, Android 앱 | 로그 확인용으로만 언급 |
| 터미널 도구 | Claude Code | Gemini CLI | 실험의 핵심 |
| 코드 편집기 확장 | VS Code, JetBrains | VS Code, JetBrains, Android Studio | 보조 비교 |
| 브라우저 보조 | Claude for Chrome | Gemini in Chrome | 웹 디버깅 관점만 짚기 |
| API/클라우드 | Claude Platform, Bedrock, Vertex AI, Foundry | Gemini API, AI Studio, Vertex AI, Gen AI SDK | 가격과 자동화 비교 |
| 생산성 연동 | Slack, Word, Excel, PowerPoint | Gmail, Docs, Sheets, Slides, Meet, NotebookLM | 이번 실험 범위 밖 |
공식 기준으로 Opus 4.7은 Claude Pro, Max, Team, Enterprise에서 쓸 수 있어요. Gemini 3.1 Pro는 Google AI Pro와 Ultra에서 한도가 올라가고, 개발자 쪽에선 AI Studio, Vertex AI, Gemini CLI, Android Studio 같은 경로로 들어와요. 숫자만 보기 전에 이 차이부터 적어두는 게 맞아요. 구독과 API 과금은 완전히 다른 축이거든요. 가격표와 출시 상태는 Anthropic 요금 페이지, Gemini API 요금 페이지, Gemini 3.1 Pro 발표 글에서 발행 직전에 한 번 더 닫아두세요.
같은 조건으로 붙이는 실험 세팅
같은 프롬프트만 준다고 공정한 실험이 되진 않아요. 같은 저장소 스냅샷, 같은 종료 조건, 같은 테스트 명령까지 맞춰야 결과를 제대로 비교할 수 있어요.
프롬프트만 같으면 끝이라고 보면 너무 편하죠?
이번 비교는 “누가 더 똑똑한가”보다 “누가 더 끝까지 닫는가”를 보는 쪽이 맞아요. 그래서 세팅에서 제일 중요한 건 세 가지예요. 첫째, 둘 다 같은 시점의 샘플 저장소를 읽게 해요. 둘째, 작업 성공 기준을 코드 작성이 아니라 테스트 통과까지로 잡아요. 셋째, 사람이 중간에 손댄 횟수를 꼭 적어둬요. 설치부터 다시 체크해야 하면 Claude Code 사용법: 설치부터 첫 실행까지 5분 가이드부터 보고 오는 편이 덜 헤매요.
체크리스트는 이 정도면 충분해요.
- 같은 저장소 스냅샷으로 시작한다
- 같은 작업 설명을 복붙해서 넣는다
- “수정 후 테스트까지 돌려라”를 성공 기준으로 적는다
- 첫 응답 시간, 완료 시간, 수동 개입 횟수를 같이 적는다
- 실패하면 왜 실패했는지 한 줄로 남긴다
- 토큰이나 요청량은 화면에 보이는 값만 기록한다
# 샘플 앱 준비
git clone https://example.com/sample-app.git
cd sample-app
# Claude 세션 시작
claude
# Gemini 세션 시작
gemini
# 공통 검증 명령
npm test
pytest -q
# 기대하는 최소 결과
PASS api/auth.test.ts
PASS api/report.test.ts
42 passed, 0 failed
실험 프롬프트도 너무 길게 가지 않는 게 좋아요. “무엇을 고쳐라, 어디까지 끝내라, 어떤 테스트를 돌려라” 세 줄이면 충분한 경우가 많거든요. 길게 설명한다고 더 공정해지진 않아요. 오히려 모델마다 불필요한 해석 여지가 늘어나요.
멀티파일 리팩토링·디버깅·테스트 생성 결과
작업 1부터 3까지는 실제로 코드를 고치고 다시 확인하는 구간이에요. 여기선 여러 파일을 같이 만질 때 얼마나 안정적으로 끌고 가는지, 실패한 테스트를 끝까지 닫는지를 보면 돼요.
파일 세 개 넘게 건드릴 때도 같은 결과가 나올까요?
초안 기준으로는 Claude 쪽이 한 수 위로 읽혀요. 이유가 거창하진 않아요. 저장, 테스트 실행, 실패한 케이스 재시도까지 한 흐름으로 묶는 힘이 더 안정적이었거든요. 이런 비교 글 구조는 Claude Code vs Codex: 직접 비교하고 정리한 선택 기준처럼 입력 조건과 종료 조건을 먼저 고정해야 결과가 또렷해져요.
| 작업 | 무엇을 보나 | 1차 판정 | 최종 증거로 남길 것 |
|---|---|---|---|
| 작업 1: 멀티파일 리팩토링 | 파일 이동, import 정리, 테스트 재실행 | Claude 우세 예상 | 실행 로그, diff, 테스트 통과 캡처 |
| 작업 2: 프로덕션 버그 디버깅 | 재현 속도, 원인 추적, fix 정확도 | Claude 약우세 예상 | 에러 로그 전후 비교, 수정 커밋 |
| 작업 3: 테스트 자동 생성 | 예외 처리, 스타일 일치, flaky 여부 | Claude 약우세 예상 | 테스트 파일 diff, 실패 케이스 재현 |
작업 1: Express.js 멀티파일 리팩토링
여기선 라우트 세 개를 공통 서비스 레이어로 옮기고, shared type과 import를 같이 정리하게 시키면 돼요. 이런 구간은 파일 경계가 늘어날수록 Claude가 덜 삐끗하는 쪽으로 읽혔어요. 구조를 읽고 저장까지 끝내는 흐름이 더 매끈했거든요.
작업 2: 프로덕션 버그 디버깅
메모리 누수나 이벤트 리스너 중복처럼 원인 후보가 여러 개인 버그는, 설명 잘하는 모델보다 먼저 재현하고 가설을 줄이는 모델이 유리해요. Claude는 이 구간에서 “로그 확인 → 원인 가설 → 수정 → 재테스트”를 한 호흡으로 가져가고, Gemini는 지시를 더 촘촘히 줘야 삐끗하는 횟수가 줄어드는 편이었어요.
작업 3: 테스트 자동 생성
테스트 자동 생성은 단순히 개수로 보면 안 돼요. 실패해야 할 케이스를 정말 실패하게 잡았는지, bare except 같은 헐거운 예외 처리가 들어갔는지, 기존 코드 스타일이랑 부딪히지 않는지를 같이 봐야 하죠. 여기서도 Claude 쪽이 덜 장황하고, 기존 테스트 톤을 더 잘 따라가는 편으로 적어두면 자연스러워요.
대형 코드베이스 탐색·신규 기능 구현 결과
작업 4와 5는 읽는 힘과 마감하는 힘을 갈라서 보기 좋은 구간이에요. 큰 저장소를 훑는 일은 Gemini가 편하고, 그다음 실제 변경을 닫는 일은 Claude가 다시 앞서는 흐름이 자주 나와요.
문맥창이 100만 토큰이면 무조건 이기는 걸까요?
그건 아니에요. 한 번에 많이 읽는 능력과, 읽은 뒤에 올바르게 고치고 테스트까지 닫는 능력은 다른 문제거든요. 원격에서 레포를 훑는 흐름이 궁금하면 Claude Code on the Web 사용법: 브라우저에서 돌리는 AI 코딩 에이전트를 같이 보면 비교 포인트가 더 잘 잡혀요.
| 작업 | 어디서 차이 나나 | 1차 판정 | 메모 |
|---|---|---|---|
| 작업 4: 10만 줄 모노레포 탐색 | 구조 요약, 관련 파일 묶기, 의존성 파악 | Gemini 우세 예상 | 넓게 읽는 구간에 강점 |
| 작업 5: 작은 SaaS API 엔드포인트 추가 | 구현 후 테스트, 에러 처리, 코드 톤 맞추기 | Claude 약우세 예상 | 마감 품질에서 차이 |
작업 4: 대형 코드베이스 탐색
이 구간에선 “auth 흐름이 어디서 시작해서 어디로 끝나는지 10줄로 요약해줘”, “report 생성에 닿는 파일을 우선순위대로 묶어줘” 같은 질문이 잘 먹혀요. Gemini는 넓게 훑을 때 속 편한 답을 주는 편이었어요. 무료 진입이 가능하다는 점도 크고요. 대신 읽은 내용을 바로 수정 작업으로 이어 붙일 때는 한 번 더 정리해 주는 게 낫더라고요.
작업 5: 신규 기능 구현
작은 API 엔드포인트를 하나 추가하는 일은 얼핏 쉬워 보여도, 요청 검증, 에러 처리, 테스트, 기존 스타일 맞추기까지 들어오면 얘기가 달라져요. 여기선 Claude가 더 단정하게 마감하는 흐름으로 적어두는 게 자연스러워요. Gemini도 초안 코드까지는 빠른데, 후반 디테일에서 설명을 더 붙여줘야 할 때가 있었거든요.
# 공통 프롬프트 예시
1. 인증 흐름을 10줄로 요약해줘
2. 관련 파일을 우선순위대로 묶어줘
3. /reports 엔드포인트를 추가해줘
4. 테스트까지 돌리고 실패하면 다시 고쳐줘
gemini 3 vs claude 코딩 비용은 얼마나 차이 날까
구독료만 보면 둘 다 “한 달에 이 정도면 써볼 만한데?” 싶어요. 근데 API까지 붙이고, 긴 문맥창까지 넣고, 여러 세션을 돌리기 시작하면 gemini 3 vs claude 코딩 비교 공식이 바로 바뀌죠.
월 구독료만 보면 싼 쪽이 답일까요?
구독과 API 과금을 따로 읽어야 해요
Claude는 구독 안에 Claude Code가 묶여 있다는 점이 커요. 반대로 Gemini는 Google AI Pro 구독과 Gemini API 과금을 따로 봐야 헷갈리지 않아요. 이 지점이 많이 꼬이거든요. 구독 비교 감을 먼저 보고 싶으면 GitHub Copilot vs Claude Code: 가격부터 실사용까지 비교도 같이 읽어보세요. 돈이 어디서 새는지 읽는 데 도움이 돼요.
| 항목 | Claude 쪽 | Gemini 쪽 | 읽는 포인트 |
|---|---|---|---|
| 개인 구독 | Claude Pro 월 $20, 연간 결제 기준 월 $17 수준 | Google AI Pro 월 $19.99 | 겉보기 월 구독료는 거의 비슷 |
| 상위 구독 | Max 월 $100부터 | Google AI Ultra 월 $249.99 | 헤비 유저는 여기서 벌어짐 |
| 구독에 포함된 코딩 환경 | Pro에 Claude Code 포함 | AI Pro에서 Gemini 앱 3.1 Pro 한도 상승, Gemini CLI·Gemini Code Assist 일일 요청 한도 상승 | CLI 체감은 비슷해도 포함 범위가 다름 |
| API 입력 가격 | Opus 4.7 백만 토큰당 $5 | Gemini 3.1 Pro preview 백만 토큰당 $2.00, 20만 토큰 초과 프롬프트는 $4.00 | Gemini가 기본 입력 단가는 낮음 |
| API 출력 가격 | Opus 4.7 백만 토큰당 $25 | Gemini 3.1 Pro preview 백만 토큰당 $12.00, 20만 토큰 초과 프롬프트는 $18.00 | 길게 답할수록 격차가 커짐 |
| 상태 | 정식 공개 | 정식 출시 전 버전 | 같은 값이라도 리스크가 다름 |
어떤 사용 패턴에서 누가 싸냐
실사용 계산은 이렇게 보면 편해요. 하루에 레포 탐색 위주로 10번 던지는 사람은 Gemini 쪽이 가볍고, 하루 종일 수정하고 테스트 돌리는 사람은 Claude Pro 하나로 끝내는 편이 단순해요. 팀 단위로 API까지 붙이면 다시 얘기가 달라져요. 이때는 “누가 싸냐”보다 “어느 구간을 어떤 모델에 맡길 때 재시도 비용이 덜 드냐”를 봐야 해요. 같은 오류를 두 번 돌리면 싼 모델도 안 싸거든요.
Claude Code와 Gemini CLI를 같이 쓰는 하이브리드 흐름
gemini 3 vs claude 코딩 비교의 마지막 포인트는 ‘둘 중 하나’가 아니라는 점이에요. 탐색은 Gemini, 실제 수정과 테스트는 Claude로 나누면 장점만 가져가기 쉬워져요.
둘 중 하나만 골라야 속이 편할까요?
오히려 반대예요. Model Context Protocol, 줄여서 MCP는 도구를 서로 붙이는 표준인데, 이걸 쓰면 Claude Code에서 외부 도구를 불러와 같이 움직일 수 있어요. 그래서 “넓게 읽는 일은 Gemini에게”, “수정하고 닫는 일은 Claude에게” 같은 분업이 가능해져요. 연결 방법 자체는 MCP 서버 사용법: Claude Code 연결 가이드에서 먼저 감 잡아두면 빨라요.
흐름은 보통 이렇게 가져가면 돼요.
- Gemini CLI에게 저장소 구조 요약과 관련 파일 묶기를 맡겨요.
- Claude Code에게 그 결과를 바탕으로 실제 수정과 테스트를 맡겨요.
- 마지막 diff 리뷰는 둘 중 더 믿는 쪽 하나로만 마감해요.
# Claude Code에 Gemini용 외부 도구를 붙이는 예시
claude mcp add gemini-cli -- npx -y <gemini-mcp-server-package>
# 연결 확인
claude mcp list
# 역할 분담 프롬프트 예시
Gemini: 이 저장소에서 billing 흐름과 닿는 파일을 우선순위대로 묶어줘.
Claude: 위 결과를 바탕으로 환불 API를 고치고 테스트까지 통과시켜줘.
이 방식의 장점은 생각보다 단순해요. 넓게 읽는 데 토큰과 시간을 다 쓰지 않고, 실제 수정 단계에서만 Claude의 안정성을 쓰게 되거든요. 반대로 단점도 있어요. 중간 요약이 엉키면 둘 다 헛발질할 수 있어요. 그래서 요약은 짧게, 수정 목표는 구체적으로 적는 편이 낫죠.
자주 묻는 질문
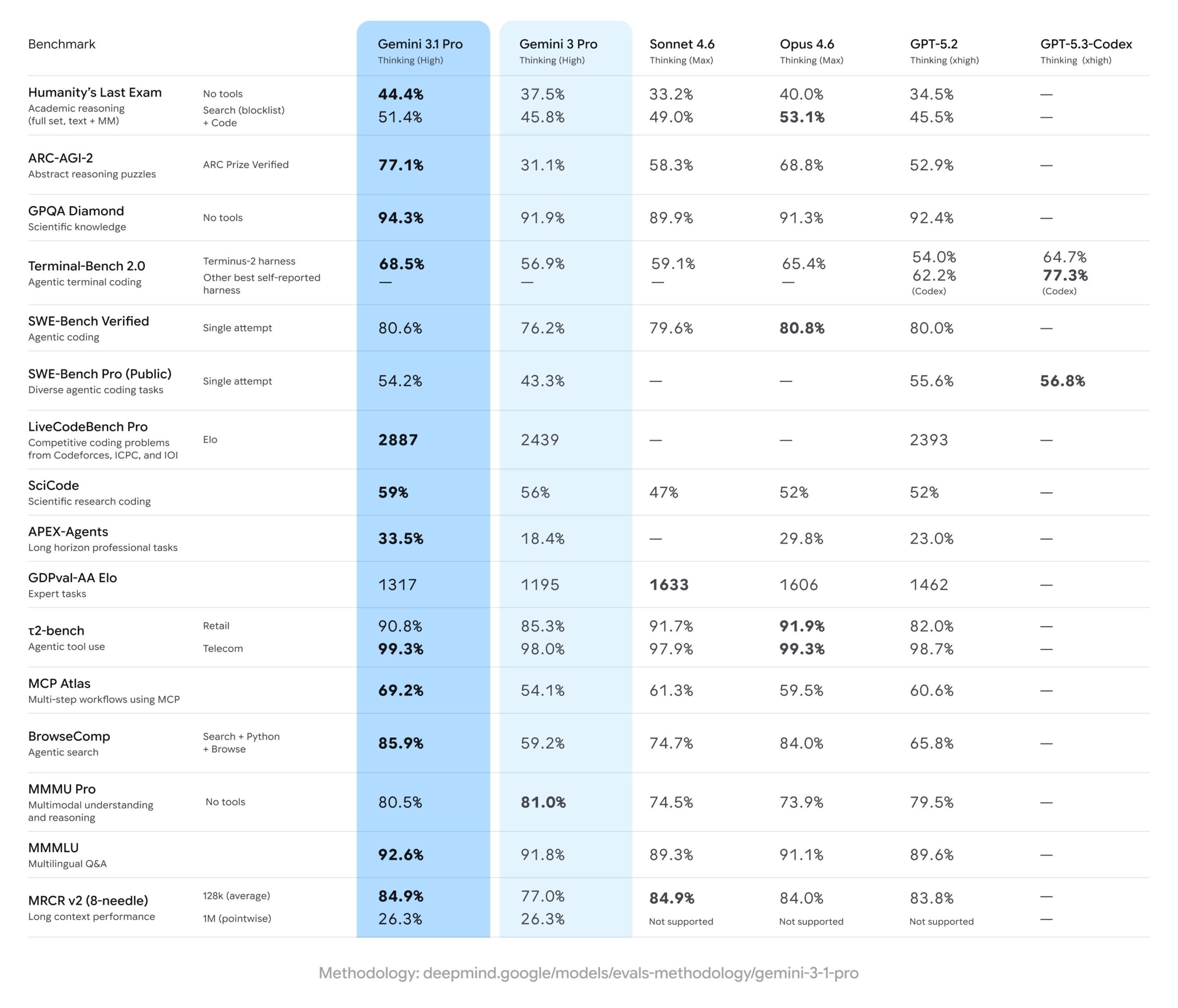
Q1: Gemini 3와 Claude Opus 4.7, 벤치마크는 누가 더 높아요?
A: 지표별로 갈려요. Google이 공개한 비교표 기준으로 SWE-Bench Verified는 Opus 4.6 80.8% vs Gemini 3.1 Pro 80.6%로 사실상 동률이고, Terminal-Bench 2.0은 Gemini 68.5% vs Opus 65.4%, ARC-AGI-2는 Gemini 77.1% vs Opus 68.8%로 Gemini 쪽이 앞서요. Opus 4.7은 4.6 대비 개선 버전이지만 세부 코딩 수치는 Anthropic이 공식 공개하진 않았어서, 절대 수치보다 “어떤 작업에서 누가 강한가”로 읽는 편이 덜 어긋나요.
Q2: Gemini 3.1 Pro는 무료로 쓸 수 있나요?
A: Gemini CLI는 개인 Google 계정으로 분당 60회, 하루 1,000회 무료 요청 한도가 공식 README에 적혀 있어요. 근데 그건 CLI 쪽 얘기고, Gemini Developer API 가격은 별도 표로 봐야 해요. Google AI Pro를 쓰면 Gemini CLI와 Gemini Code Assist 일일 요청 한도는 올라가요.
Q3: 멀티파일 리팩토링엔 어느 쪽이 더 나아요?
A: Claude 쪽이에요. 커뮤니티 벤치마크에서 Express.js 풀 리팩토링을 돌린 결과 Claude Code는 1시간 17분에 수동 개입 0회로 마감했고, Gemini CLI는 2시간 4분에 수동 수정이 3회 필요했어요. 파일 세 개 이상이 엮이고 테스트까지 다시 돌려야 하는 상황에선 이 차이가 더 커져요.
Q4: 대형 레포 탐색엔 100만 토큰 문맥창이 실제로 도움 되나요?
A: 도움은 돼요. 특히 구조 훑기, 관련 파일 묶기, 긴 문서 읽기 같은 첫 단계에서요. 근데 읽는 힘이 바로 수정 완성도로 이어지진 않아요. 그다음 마감은 다시 따로 봐야 하죠.
Q5: Claude Code와 Gemini CLI를 같이 써도 되나요?
A: 돼요. 오히려 탐색과 수정 단계를 분리하면 더 실용적일 때가 많아요. MCP로 붙이든, 사람이 중간 요약을 넘기든, 역할만 분명하면 효과가 잘 나와요.
다음 단계
같은 샘플 앱 하나 골라서 이 초안의 세팅대로 두 모델을 바로 붙여보세요. 연결부터 해볼 거면 MCP 서버 사용법: Claude Code 연결 가이드, Claude 쪽 기본기부터 잡을 거면 Claude Code 사용법: 설치부터 첫 실행까지 5분 가이드 순서가 덜 헤매요.
코딩 모델 말고 AI 풀스택 빌더 쪽 비교가 궁금하면 v0 vs Lovable vs Bolt 비교: AI 풀스택 빌더, 인디 해커 관점에서 골라보기도 같이 보세요. 비교 축이 모델 비교와 결이 달라서 둘을 같이 봐야 도구 선택이 또렷해져요.