Claude Code MCP 500K 컨텍스트: 대형 문서·DB 한 번에 읽히기
Claude Code MCP 500K 한 줄 요약
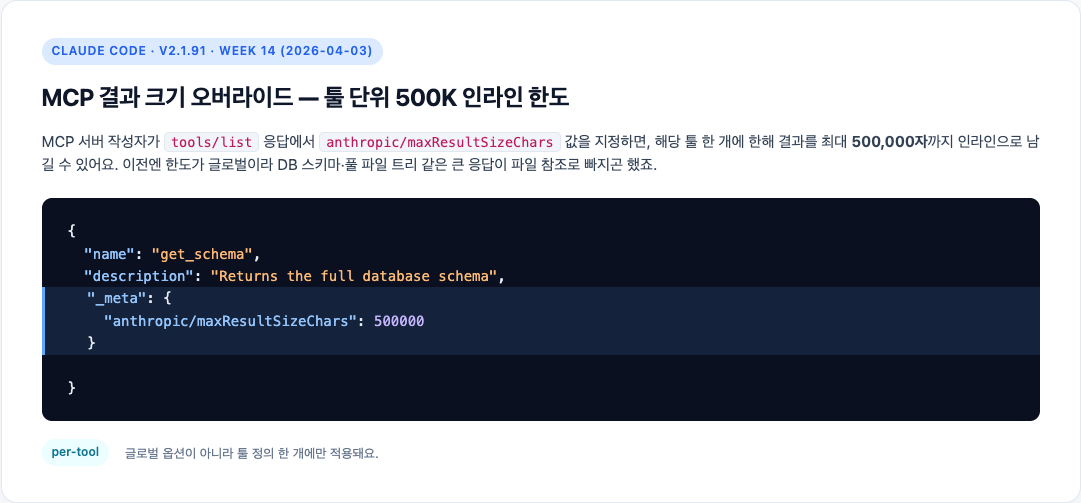
Claude Code MCP 500K는 2026년 4월 공개된 v2.1.91에서 들어온 툴별 결과 크기 상한이에요. 줄여 쓰면 의미가 깨지는 텍스트(스키마·명세·풀 파일 트리)에만
_meta["anthropic/maxResultSizeChars"]를 붙이고, 단발성 로그까지 다 열어두면 세션 후반 답 품질이 떨어져요.
GitHub MCP 하나 붙였는데 시작하자마자 컨텍스트가 훅 빠진 적 있었어요. 그 상태에서 500K 풀렸다는 말만 보면 이제 큰 응답은 다 넣어도 되겠다고 생각하기 쉬워요. 근데 Claude Code MCP 500K는 전체 세션 한도가 늘어난 얘기가 아니에요. 2026-04-03에 공개된 v2.1.91 Week 14 릴리스 노트 기준으로, 특정 MCP 툴 결과를 인라인으로 더 길게 남길 수 있게 된 거죠. 이게 왜 모든 툴 결과 한도가 아니라 툴별 한도가 됐는지부터 보면, 켜고 끌 자리가 자연스럽게 갈려요. 여기서는 _meta["anthropic/maxResultSizeChars"]를 어디에 붙이는지, 사용자가 건드릴 수 있는 MAX_MCP_OUTPUT_TOKENS랑 뭐가 다른지, GitHub MCP처럼 툴 수가 많은 서버에선 왜 Tool Search랑 툴셋 제한을 같이 봐야 하는지까지 묶어서 정리할게요. MCP 연결 자체가 아직 낯설면 MCP 서버 사용법: Claude Code 연결 가이드부터 보고 오면 훨씬 빨라요.
2026년 4월 기준 Claude Code MCP 500K가 바꾼 것
그래서 전체 컨텍스트가 500K로 늘어난 건가 싶죠? 그건 아니에요.
네, 세션 컨텍스트가 늘어난 게 아니라 특정 MCP 툴 결과 한 번에만 길게 인라인을 허용해 주는 옵션이 새로 생긴 거예요. 2026-04-26 기준 Claude Code는 터미널 CLI, VS Code 확장, JetBrains 플러그인, 데스크톱 앱, 웹, Claude iOS 앱, Slack, Chrome 연동, CI/CD 자동화, Agent SDK 같은 개발자용 진입점까지 넓게 퍼져 있어요. 그런데 anthropic/maxResultSizeChars는 이 사용 환경 어디에서도 누르는 버튼이 아니에요. MCP 서버가 tools/list 응답에 직접 선언해야 하고, 그때만 해당 툴 하나에 예외가 생기죠. 공식 Week 14 릴리스 노트도 이걸 per-tool override로 설명해요.
| 항목 | 지금 바뀐 것 | 그대로인 것 |
|---|---|---|
| 적용 위치 | 특정 MCP 툴 결과 상한 | 세션 전체 컨텍스트 크기 |
| 기준 단위 | 500,000자 (per-tool) | 경고 10K · 기본 한도 25K 토큰 |
| 누가 켜나 | MCP 서버 작성자 | 사용자는 서버 어노테이션을 직접 못 켬 |
| 잘 맞는 데이터 | 스키마, 명세, 풀 파일 트리 | 단발성 로그, 한 번 보고 끝나는 검색 결과 |
웹 원격 세션에서 어디까지 공유되고 어디서 헷갈리는지 같이 보려면 Claude Code on the Web 사용법: 브라우저에서 돌리는 AI 코딩 에이전트도 같이 보면 좋아요. 화면은 달라도, 어노테이션이 붙는 자리는 결국 서버 응답 한 군데거든요.
또 한 가지 자주 헷갈리는 건 “Claude Code MCP 500K”가 컨텍스트 윈도우 자체와 묶여 있다고 보는 시각인데요. v2.1.91 릴리스 노트와 공식 MCP 문서에서도 이 옵션을 per-tool override로 분류해 둬요. 같은 세션에 다른 MCP 툴이 10개 더 있어도, 이 어노테이션은 옵트인한 한 툴의 결과 한 번에만 적용된다는 점만 기억하면 돼요.
anthropic/maxResultSizeChars 적용법
서버 쪽 어노테이션 한 줄과 사용자 쪽 환경 변수 하나, 두 다이얼이 따로 있어요. 이름이 비슷해서 헷갈리지만 하나는 툴 정의에 붙고 하나는 실행 환경에서만 동작하죠.
근데 어노테이션 한 줄을 어디에 붙이느냐가 진짜 결정 아니에요?
맞아요, 한 줄을 어디에 붙이느냐가 더 중요해요. 실무에선 보통 요약 툴 하나, 전체 참조 툴 하나로 나누는 게 편해요. 같은 스키마를 다루더라도 매번 300KB짜리 본문을 넣는 건 손해가 크거든요. 그래서 기본 툴은 짧게, 정말 필요할 때만 전체 툴을 고르게 만드는 식으로 가면 덜 삽질해요. 이 패턴은 MCP 서버 직접 만들기: Python FastMCP 30분 빌드 가이드에 있는 서버 구조를 확장할 때도 바로 써먹기 좋아요.
예시: 툴 두 개로 나누기
def list_tools():
return [
{
"name": "get_schema_summary",
"description": "스키마를 짧게 요약해서 반환",
},
{
"name": "get_schema_full",
"description": "테이블, 컬럼, 제약조건을 전체 텍스트로 반환",
"_meta": {
"anthropic/maxResultSizeChars": 300000
},
},
]
예시: 사용자 쪽에서 할 수 있는 일
# MCP 출력 경고 한도를 올리고 Claude Code 시작
export MAX_MCP_OUTPUT_TOKENS=50000
claude
# 세션 안에서 서버 연결 상태 확인
/mcp
예상 흐름은 이래요.
Loaded MCP server: db-tools
Available tools: get_schema_summary, get_schema_full
> get_schema_full 한 번 불러와 줘
Result returned inline for get_schema_full (287,412 chars)
[Claude] 스키마 받았어요. 핵심 테이블 12개, FK 28개부터 정리할게요.
핵심은 둘을 섞지 않는 거예요. MAX_MCP_OUTPUT_TOKENS는 경고선과 일반 제한을 바꾸고, _meta["anthropic/maxResultSizeChars"]는 특정 텍스트 툴의 인라인 상한을 직접 올려줘요. 공식 MCP 문서 기준으로 텍스트는 어노테이션이 우선이고, 이미지 데이터는 여전히 MAX_MCP_OUTPUT_TOKENS를 타요.
Claude Code MCP 500K를 켜야 할 툴과 끌 툴
설마 로그 덤프까지 전부 인라인으로 밀어 넣고 있는 건 아니죠?
보통은 로그 덤프야말로 500K가 가장 손해 보는 자리예요. 반복 참조 여부, 요약 손실, 재호출 가능성 이 세 가지만 보면 대부분 결정이 갈려요.
Claude Code MCP 500K를 켜야 할 3가지 조건
제가 먼저 보는 기준은 세 가지예요. 첫째, 한 세션에서 여러 번 다시 볼 데이터인가. 둘째, 칼럼명이나 타입처럼 한 글자만 달라도 의미가 바뀌는가. 셋째, 파일 시스템이나 다른 툴로 쉽게 다시 읽어올 수 없는가. 이 셋이 겹치면 500K 쪽이 맞는 편이에요. 반대로 한 번 보고 요약만 남기면 되는 출력은 기본 제한이 오히려 덜 아파요.
| 툴 유형 | 500K 권장 여부 | 이유 | 더 나은 패턴 |
|---|---|---|---|
| DB 스키마 전체 조회 | 예 | 여러 턴에 반복 참조하고 축자 정보가 중요함 | 요약 툴 + 전체 툴 분리 |
| OpenAPI/GraphQL 전체 명세 | 예 | 필드명, 타입, 제약조건이 빠지면 곧바로 틀어짐 | 전체 툴을 선택형으로 노출 |
| 대형 파일 트리 | 경우에 따라 예 | 구조 파악엔 유용하지만 매턴 넣으면 무거움 | 필요할 때만 전체 툴 호출 |
| 단발성 로그 덤프 | 보통 아니오 | 요약이나 grep 결과만 있어도 충분한 경우가 많음 | 요약 툴, 필터 툴 먼저 |
| GitHub MCP처럼 툴이 많은 서버 | 아니오 | 문제는 결과 길이보다 툴 정의 수인 경우가 많음 | Tool Search, 툴셋 제한, 개별 툴 제한 |
한눈에 보는 빠른 체크리스트
빠르게 체크하려면 아래처럼 보면 돼요.
- 여러 턴에서 다시 꺼내 볼 자료다
- 줄여 쓰면 컬럼명, 옵션값, 제약조건이 사라진다
- 다른 경로로 다시 읽어오기 번거롭다
위 세 줄에 다 체크되면 500K 후보예요.
반대로 결과 크기보다 연결 안정성이 먼저 의심되는 상황이라면, MCP 서버 설치부터 다시 보는 쪽이 낫고요. 연결이 들쭉날쭉한 상태에서 결과 크기부터 올리면 원인을 찾기가 더 어려워져요.
500K를 남용하면 왜 세션 후반에 답 품질이 떨어질까
근데 진짜 체감이 있냐고요?
있어요. 커뮤니티에선 가끔 dumb zone(컨텍스트는 차 있지만 답이 무뎌지는 구간)이라고 부르는데, 쉽게 말하면 컨텍스트는 가득 차 있는데 정작 모델이 필요한 데 집중을 못 하는 상태예요. Claude Code 공식 컨텍스트 문서도 세션 안엔 지침, 파일 읽기, 툴 정보, 응답 요약이 계속 쌓인다고 설명하거든요. 여기에 200KB, 300KB짜리 텍스트를 몇 번만 인라인으로 넣으면 처음엔 좋다가도 뒤쪽 턴에서 컬럼명 하나, 옵션 이름 하나를 놓치기 쉬워져요.
이럴 때 보이는 신호는 대충 이렇더라고요.
- 방금 본 스키마인데 테이블 이름을 헷갈려요
- 같은 질문을 다시 했을 때 답의 기준이 자꾸 어긋나요
- 예전 턴에서 본 긴 덤프를 계속 붙잡고 새 정보 반영이 느려져요
제 경우엔 한 번 큼직한 OpenAPI 명세를 모든 툴에 다 인라인으로 넣고 작업하다가 7~8턴쯤부터 답이 미묘하게 어긋나기 시작했어요. 처음엔 단순한 오타 정도였는데, 12턴 넘어가니까 직전에 이미 말한 엔드포인트를 다시 헷갈리더라고요. 그때부터 Claude Code MCP 500K 어노테이션을 꼭 필요한 툴에만 남기고 나머지는 다시 기본값으로 내렸더니, 같은 길이 세션에서 같은 종류 실수가 확연히 줄었어요. 컨텍스트가 가득 찬다고 모델이 더 똑똑해지는 게 아니라는 걸, 한 세션 사이에서 가장 분명하게 느낀 순간이었어요.
완화법도 단순해요. 전체 참조 툴은 정말 필요할 때만 쓰고, 나머지는 요약 툴로 돌리세요. 긴 탐색 작업은 본 세션에 다 밀어 넣지 말고 분리하는 편이 낫고요. 공식 문서 기준으로 서브에이전트는 별도 컨텍스트에서 일하고 요약만 돌아오니까, 큰 자료 읽기를 떼어내고 싶을 땐 Claude Code 서브에이전트 만들기 실전 가이드: 자동 위임·비용 절감 세팅까지가 꽤 잘 맞아요.
Tool Search와 GitHub MCP 툴셋 제한도 같이 보기
이거 GitHub MCP에도 바로 통하는 거 아니에요?
꼭 그렇진 않아요. GitHub MCP에서 답답한 경우는 응답 길이보다 툴 수가 먼저 문제일 때가 많거든요. 실제 GitHub MCP Issue #1286에도 서버를 붙이자 시작 컨텍스트가 34K에서 80K로 뛰었다는 보고가 있어요. 이건 500K를 켠다고 풀리는 성질이 아니에요. 공식 Anthropic 문서 기준으로 Tool Search는 필요한 도구만 뒤에서 불러오고, GitHub 공식 문서와 원격 서버 문서는 X-MCP-Toolsets나 X-MCP-Tools로 범위를 줄일 수 있다고 안내해요.
{
"mcpServers": {
"github": {
"type": "http",
"url": "https://api.githubcopilot.com/mcp",
"headers": {
"Authorization": "Bearer YOUR_GITHUB_PAT",
"X-MCP-Toolsets": "repos,issues,pull_requests,actions"
}
}
}
}
# MCP 툴 정의가 컨텍스트의 5% 이상을 차지할 때부터 Tool Search 자동 활성화
# (기본 auto는 10% 임계치 — auto:N은 N%로 더 보수적/공격적 조정)
ENABLE_TOOL_SEARCH=auto:5 claude
# 명시적으로 끄기
ENABLE_TOOL_SEARCH=false claude
긴 세션을 원격으로 오래 돌릴수록 시작 컨텍스트 낭비가 더 거슬려요. 그래서 원격 작업 흐름을 같이 보는 Claude Code Remote Control 사용법: 폰에서 이어받고 VPS에서 돌리기와 묶어서 보면 감이 빨라요. 500K는 “큰 결과를 남겨도 되나”의 문제고, Tool Search와 툴셋 제한은 “애초에 뭘 먼저 싣고 시작하나”의 문제거든요.
시작 컨텍스트가 얼마나 빠지는지 — 커뮤니티 실측
수치 감각 잡기엔 커뮤니티 보고가 직관적이에요. Medium의 한 실측 글은 Claude Code의 Tool Search를 켰더니 시작 시 MCP 툴 정의 토큰이 51K → 8.5K로 줄었다고 보고했어요(약 46.9% 절감). dev.to의 다른 글은 MCP 서버 3개를 동시에 붙이면 200K 컨텍스트의 72%인 약 143K 토큰이 툴 정의에만 잡혀서, 실제 작업에 57K밖에 안 남는다고 정리했고요.
이런 환경에서 모든 툴에 Claude Code MCP 500K를 켜 두면, 가뜩이나 좁은 작업 컨텍스트에 큰 응답까지 더 얹히는 셈이라 “왜 후반엔 답이 떨어지지” 같은 의문이 자연스럽게 생기게 돼요. 같은 맥락에서 GeekNews에서 회자된 Context Mode(98% 압축 MCP)도 대안이긴 한데, 스키마처럼 축자성이 중요한 데이터엔 정보 손실이 거슬려서 Claude Code MCP 500K 인라인 쪽이 더 맞다는 의견이 다수였어요.
자주 묻는 질문
짧게 끊어 답할게요.
Q1: 700자 정도로 잘리던 문제는 이제 끝난 건가요?
A: 이슈 자체가 fix로 닫혔다고 말하긴 어려워요. 2026-04-26 기준 anthropic/claude-code 리포의 이슈 #2638은 Closed as not planned 상태인데, v2.1.91에서 툴별 결과 크기 오버라이드가 들어오면서 텍스트형 도구는 서버 작성자가 어노테이션을 붙이면 사실상 우회가 가능해졌어요. 다만 큰 응답에서 UI가 멈추는 계열 이슈는 별개로 남아 있는지 사람이 한 번 더 봐야 해요.
Q2: 500K는 토큰인가요, 문자인가요?
A: 공식 MCP 문서와 Week 14 릴리스 노트 기준으로 500K는 문자 기준이에요. 반대로 MAX_MCP_OUTPUT_TOKENS는 토큰 기준이라서, 이름이 비슷해도 같은 다이얼이 아니죠.
Q3: 데스크톱, VS Code, Web에서도 제가 따로 켜야 하나요?
A: 아니에요. CLI든 데스크톱이든 VS Code든, 이 스위치는 항상 MCP 서버의 tools/list에만 있어요. 사용자가 따로 켤 자리가 없는 게 정상이에요.
Q4: GitHub MCP가 무거운 것도 500K로 해결되나요?
A: 보통 아니에요. GitHub MCP는 큰 결과보다 툴 정의 수가 먼저 컨텍스트를 먹는 경우가 많아서 Tool Search, X-MCP-Toolsets, X-MCP-Tools 쪽이 먼저예요. 500K는 개별 응답이 잘리지 않게 하는 쪽에 가까워요.
Q5: 서버 작성자가 아니면 제가 할 수 있는 건 뭐예요?
A: 어노테이션 자체는 못 붙여요. 대신 MAX_MCP_OUTPUT_TOKENS를 조정하고, Tool Search를 명시하고, 툴셋이나 개별 툴 범위를 줄이는 식으로 세션 부담을 낮출 수 있어요.
Q6: Context Mode(98% 압축 MCP)와 500K 중에 뭘 쓰는 게 맞나요?
A: 데이터 성격에 따라 달라요. Context Mode는 MCP 출력을 서브프로세스에서 처리해 거의 1/50로 압축하는 오픈소스 프록시인데, 단순 텍스트나 로그 요약엔 효율적이에요. 다만 DB 스키마, 코드, JSON 명세처럼 한 글자 차이로 의미가 달라지는 데이터엔 압축이 위험해요. 그래서 축자성이 중요한 자료는 Claude Code MCP 500K 어노테이션으로 인라인을 유지하고, 단발성 출력은 Context Mode나 요약 툴 쪽이 더 맞아요. 둘은 경쟁이 아니라 데이터 종류별 분담에 가깝다고 보면 돼요.
Q7: 500K를 모든 MCP 툴에 그냥 기본값으로 깔아두면 안 되나요?
A: 권장하지 않아요. 모든 툴에 깔아 두면 한 세션 안에 큰 응답이 누적되면서 어텐션이 분산되고, 후반 턴에서 답이 떨어지는 현상이 가속돼요. 같은 도메인이라도 요약 툴과 전체 참조 툴 두 개로 나누고, 모델이 정말 필요할 때만 전체 툴을 부르게 두는 패턴이 가장 무난해요.
운영 체크리스트 — Claude Code MCP 500K 켤 때 5가지
본인 서버에 어노테이션을 한 번 붙이기 전에, 아래 5가지만 짧게 셀프 체크해 보세요. 모든 항목에 ✓가 찍혀야 Claude Code MCP 500K 어노테이션이 손해 없이 들어갈 자리예요.
- 이 툴 결과를 한 세션에서 평균 3턴 이상 다시 들춰 봐요
- 결과를 100자, 1KB 단위로 요약해 두면 모델이 자주 잘못된 추론을 해요
- 같은 데이터를 다른 툴이나 파일 시스템 호출로 다시 불러오기가 비용·UX 측면에서 부담돼요
- 같은 서버 안에 동일 도메인의 짧은 요약 툴이 따로 존재해서, 모델이 항상 전체 툴부터 부르지 않아요
- 사용 중인 다른 MCP 서버의 시작 컨텍스트가 충분히 가벼워서, 큰 응답을 얹어도 작업 컨텍스트가 절반 이하로 떨어지지 않아요
체크리스트 중 하나라도 ✗면, 해당 툴엔 Claude Code MCP 500K 어노테이션을 일단 빼두는 쪽이 안전해요. 어노테이션은 한 줄 추가가 가벼워 보이지만, 세션 전체 토큰 경제에 미치는 영향은 꽤 길게 가거든요.
다음 단계
본인 MCP 서버에 요약 툴 하나, 전체 참조 툴 하나만 먼저 나눠서 붙여보세요. 그다음 같은 작업을 한 세션에서 다시 돌려 보면, Claude Code MCP 500K를 켜야 하는 자리랑 Tool Search를 손봐야 하는 자리가 바로 갈릴 거예요.
관련 글: Claude Code /usage 분석법
관련 글: AI 풀스택 빌더 비교