Claude Opus 4.7 vs Sonnet 4.6: 코드 작업별 선택과 비용 비교
Opus 4.7 vs Sonnet 4.6 한 줄 요약
짧은 답: Sonnet 4.6을 기본값에 깔고, 멀티파일 리팩터링·장기 에이전트 세션·고해상도 화면 분석처럼 어려운 구간만 Opus 4.7로 올리면 돼요. 2026-04-25 기준 단가는 Sonnet 4.6이 입력 $3 / 출력 $15, Opus 4.7이 입력 $5 / 출력 $25고, Opus 4.7은 새 tokenizer 영향까지 겹쳐 체감 비용이 더 벌어져요.
Opus 4.7로 며칠만 돌려도 청구 대시보드부터 달라지더라고요. 공지문만 보면 기존 Opus와 같은 단가처럼 보이는데, 실제 코딩 워크플로우에 넣으면 얘기가 꽤 달라져요. Claude Opus 4.7은 어려운 멀티파일 작업에서 확실히 더 단단한 편인데, 일상 코딩까지 전부 Opus로 밀어버리면 Sonnet 4.6으로 끝날 일에 돈이 먼저 새요. 반대로 Sonnet 4.6만 고집하면 큰 리팩터링, 긴 세션, 화면 해석에서 다시 막히죠. 웹 앱, 데스크톱, 모바일, Claude Code, API, 클라우드 배포 환경까지 쓰는 곳도 넓어서 더 헷갈리고요.
그래서 필요한 건 모델 찬양이 아니라 라우팅 규칙이에요. 어디까지 Sonnet으로 버티고, 어떤 순간에만 Opus로 올릴지 정하면 청구서 변동 폭이 줄고 품질도 덜 놓쳐요. 아래에는 그 기준만 실무형으로 뽑아놨어요. Claude Code 기본 모델을 바꾸는 명령, 공식 가격표 기준 비용 차이, 토큰 수를 직접 재는 방법, 2026-04-23 Anthropic 포스트모텀 이후에 무엇을 다시 테스트해야 하는지까지 한 번에 정리했어요.
결론부터 80/20 라우팅이 맞아요
일상 코딩의 대부분은 Sonnet 4.6으로 충분하고, Opus 4.7은 어려운 구간만 쓰는 편이 제일 나아요. 공식 가격표와 Claude Code 모델 전환 문서를 같이 보면 이 패턴이 자연스럽게 나와요.
설마 단일 함수 수정까지 전부 Opus로 돌리고 있진 않죠? 그렇게 쓰면 청구서가 먼저 신호를 보내요. 작업별 추천부터 정리해 볼게요.
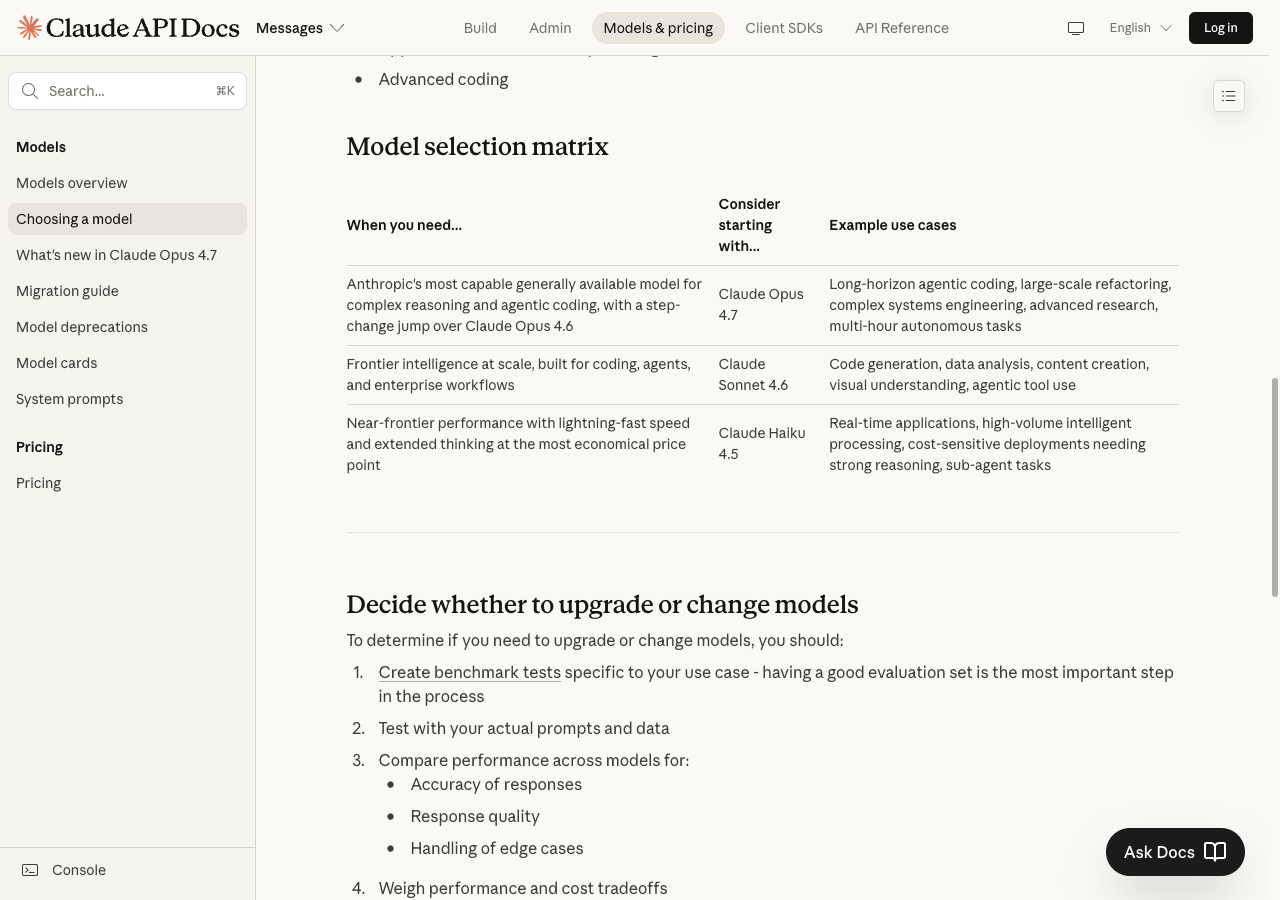
작업 유형별 추천 매트릭스
| 작업 유형 | 추천 모델 | 왜 이쪽이 맞나 |
|---|---|---|
| 단일 함수 작성·수정 | Sonnet 4.6 | 속도 빠르고 비용 부담이 적어요 |
| 짧은 코드 리뷰 | Sonnet 4.6 | 리뷰 폭보다 단가 차이가 먼저 보여요 |
| 5개 이상 파일 리팩터링 | Opus 4.7 | 멀티파일 맥락 유지가 더 단단해요 |
| 1시간 이상 장기 세션 | Opus 4.7 | 중간 계획을 오래 붙잡는 편이에요 |
| 화면 캡처·디자인 분석 | Opus 4.7 | 고해상도 비전 지원이 커졌어요 |
| 검색 붙인 응답·분류 | Sonnet 4.6 | 호출 수가 많아서 단가가 핵심이에요 |
| 비동기 대량 처리 | Sonnet 4.6 + Batch API | 50% 할인 효과가 바로 나와요 |
| 탐색용 초벌 코드 | Haiku 4.5 | 실패 비용이 낮고 회전이 빨라요 |
Sonnet 기본 + Opus escalation이 가장 덜 후회하는 이유
실무에서 가장 덜 후회하는 패턴은 간단해요. Sonnet 4.6을 기본으로 두고, 파일 수가 늘어나거나 작업 시간이 길어지거나 화면 해석이 들어오는 순간만 Opus 4.7로 올리는 거예요. Opus가 무조건 더 좋다는 얘기가 아니에요. 어려운 문제에서 더 믿을 만한 순간이 있다는 쪽에 가까워요.
Opus 쪽 강점만 따로 보고 싶으면 Claude Opus 4.7 코딩 활용법: xhigh와 비전 업그레이드로 바뀐 실전 워크플로우도 같이 보면 좋아요. 거기까지 보고 나면 “어디서 Sonnet을 끊고 Opus를 켜야 하나”가 훨씬 선명해져요.
직접 한 주 돌려본 체감으로도 비슷해요. 단일 함수 수정·짧은 디버깅은 Sonnet 4.6이 한 번에 끝내고 토큰도 덜 닳아서 굳이 Opus를 쓸 이유가 없었어요. 5개 이상 파일을 동시에 만지는 리팩터링은 Sonnet이 중간에 맥락을 흘리는 빈도가 더 컸고, Opus 4.7로 올리면 한 번에 정리되는 횟수가 늘었어요. 화면 캡처 분석은 Opus 4.7 비전이 작은 글씨까지 더 안정적으로 잡아서 다시 시키는 횟수가 줄었고요.
가격은 그대로인데 왜 더 비싸게 느껴질까
기본 단가는 Sonnet 4.6이 더 싸고 Opus 4.7이 더 비싸요. 문제는 단가표만 보면 놓치는 게 있고, Opus 4.7은 tokenizer와 응답 길이까지 같이 봐야 한다는 점이에요.
가격표만 보고 “차이 별로 없네” 하고 넘기면 청구서에서 다시 만나요.
토큰 단위 단가에 토큰 수까지 늘어나서, 표보다 실제 청구액이 더 벌어지거든요. 우선 단가표부터 정렬해 볼게요.
단가표로 본 Sonnet 4.6 vs Opus 4.7
참고로 MTok은 백만 토큰 기준이에요. 2026-04-25 기준 Anthropic 공식 가격표와 모델 페이지로 보면 차이는 이렇게 정리돼요.
| 항목 | Sonnet 4.6 | Opus 4.7 | 실무 메모 |
|---|---|---|---|
| API 입력 단가 | $3 / MTok | $5 / MTok | 시작부터 1.67배 차이 |
| API 출력 단가 | $15 / MTok | $25 / MTok | 답이 길수록 Opus 부담 큼 |
| 5분 캐시 쓰기 | $3.75 / MTok | $6.25 / MTok | 같은 system prompt 반복이면 유리 |
| 캐시 히트 | $0.30 / MTok | $0.50 / MTok | 긴 컨텍스트 재사용 때 체감돼요 |
| Batch API 입력/출력 | $1.50 / $7.50 | $2.50 / $12.50 | 비동기면 둘 다 50% 할인 |
tokenizer가 바뀌어 토큰 수까지 늘어요
근데 여기서 끝이 아니에요. Anthropic은 Opus 4.7 공지에서 입력을 토큰 단위로 쪼개는 tokenizer가 바뀌었고, 같은 입력이 대략 1.0~1.35배 더 많은 토큰으로 잡힐 수 있다고 적었어요. Simon Willison도 토큰 비교 글에서 Opus 4.7 시스템 프롬프트를 Opus 4.6과 비교해 1.46배를 봤고, 큰 PNG 이미지에서는 3.01배까지 확인했어요. Sonnet 4.6과 실제 차이는 팀에서 쓰는 system prompt로 직접 재보는 게 맞아요.
# jq가 있어야 해요
# 같은 입력으로 두 모델의 입력 토큰만 비교
for model in claude-sonnet-4-6 claude-opus-4-7; do
curl -s https://api.anthropic.com/v1/messages/count_tokens \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "content-type: application/json" \
-d "$(jq -n \
--arg model "$model" \
--arg system "You are a careful code reviewer." \
--arg prompt "Review this patch and list risks." \
'{model:$model, system:$system, messages:[{role:"user", content:$prompt}] }')" \
| jq --arg model "$model" -r '"\($model)\t\(.input_tokens)"'
done
예상 출력 형식은 이 정도면 돼요.
claude-sonnet-4-6 28
claude-opus-4-7 41
같은 system prompt 한 줄, user prompt 한 줄인데도 Opus 4.7이 약 1.46배로 잡히는 케이스를 직접 봤어요. 답이 길어지면 출력 토큰 단가까지 곱해져서 청구액 차이는 더 벌어지죠. 예산이 더 타이트하면 Claude Haiku 4.5로 비용 1/5 코딩: Opus 대신 써야 할 때는 언제?도 같이 보고, 어디까지 내릴 수 있는지 먼저 보세요.
Claude Opus 4.7 vs Sonnet 4.6 어디서 갈리나
같은 모델 비교라도 Claude 웹·모바일과 Claude Code·API는 고민 포인트가 달라요. 사용 환경(surface)을 섞어 보면 판단이 흐려져요.
웹 앱에서 답이 답답했다고 API까지 같은 결론을 내리려는 건 아니죠?
Claude를 쓸 수 있는 환경 한눈에
2026-04-25 기준 공식 페이지를 보면 Claude는 웹, iOS, Android, 데스크톱 앱, Claude Code 터미널, VS Code 확장, JetBrains IDE 확장, Claude API, Amazon Bedrock 같은 클라우드 관리형 배포 환경, Google Cloud Vertex AI, Microsoft Foundry, 그리고 Claude for Chrome·Slack·Excel·PowerPoint·Word까지 퍼져 있어요. 실무 해석으로 보면 모델 라우팅이 정말 중요해지는 곳은 Claude Code와 API 쪽이고, 웹·모바일·업무 연동은 요금제와 사용량 체감이 먼저 와요.
| 사용 환경 | 실무에서 볼 포인트 | 추천 감각 |
|---|---|---|
| Claude 웹·iOS·Android·Desktop | 구독 사용량 체감이 먼저 와요 | 기본은 Sonnet, 막힐 때만 Opus |
| Claude Code CLI | 모델 전환과 긴 세션 품질이 핵심 | Sonnet 기본, 어려우면 Opus |
| VS Code·Cursor 확장 | diff review와 선택 문맥 공유가 편해요 | 일상은 Sonnet |
| JetBrains IDE 확장 | 인텔리J 계열에서도 같은 흐름으로 가요 | 무거운 리팩터링만 Opus |
| Claude API | 토큰 단가와 batching이 그대로 보여요 | 라우팅 규칙 꼭 필요 |
| Bedrock·Vertex AI·Foundry | 별칭이 최신 버전을 바로 안 가리킬 수 있어요 | full model name 고정 |
| Chrome·Slack·Excel·PowerPoint·Word 연동 | 세밀한 라우팅보다 업무 흐름 영향이 커요 | 비용 모니터링 먼저 |
같은 Opus 4.7도 환경 따라 체감이 달라지는 이유
공식 도움말 기준으로 원격 커넥터, 그러니까 클라우드 서비스 연결 기능은 web·mobile·desktop·Claude Code 전부에 붙고, 로컬 데스크톱 확장은 Desktop과 Claude Code에서만 돌아가요. 그래서 같은 Opus라도 어떤 환경에서 길어진 문맥을 다시 읽는지가 비용과 품질에 같이 섞여 들어가요.
터미널 중심으로 비교 기준을 더 보고 싶으면 Claude Code vs Codex: 직접 비교하고 정리한 선택 기준도 같이 보세요. 모델보다 surface 차이에서 오는 불편이 뭔지 분리해서 보기 좋거든요.
Claude Code 기본 모델 바꾸기와 API 라우팅
모델 선택을 손에 익히려면 Claude Code에서 기본값을 바꾸고, API에서는 라우팅을 분리하면 돼요. 여기서부터 청구서가 실제로 달라져요.
매번 수동으로 바꾸기 귀찮다고 그냥 기본값에 맡길 건가요? 한 번 손에 익히면 매일 손댈 일은 거의 없어요.
공식 문서 기준으로 Claude Code는 /model 명령, claude --model, 환경 변수, 설정값 순서로 모델을 잡을 수 있어요. 그리고 opusplan이라는 공식 별칭도 있는데, 이건 계획 단계는 Opus로 하고 실행 단계는 Sonnet으로 넘기는 방식이에요. 하이브리드 패턴을 직접 지원한다는 뜻이죠. 참고로 Opus 4.7은 Claude Code v2.1.111(Opus 4.7 첫 지원 버전) 이상이 필요해요.
# Claude Code를 최신 버전으로 올려요
claude update
# 세션 중에 바로 Sonnet으로 전환
/model sonnet
# 계획은 Opus, 실행은 Sonnet으로 자동 분리
/model opusplan
# 처음부터 특정 모델로 시작
claude --model claude-opus-4-7
2026-04-25 기준 공식 모델 설정 문서에서 중요한 함정도 하나 있어요. Anthropic API에서는 opus가 Opus 4.7, sonnet이 Sonnet 4.6을 가리키는데, Bedrock·Vertex AI·Foundry에서는 같은 별칭이 아직 예전 버전으로 풀릴 수 있어요. 이쪽은 꼭 full model name으로 핀을 박는 게 안전해요.
# 3rd-party provider에선 버전을 핀으로 고정해요
export ANTHROPIC_DEFAULT_OPUS_MODEL=claude-opus-4-7
export ANTHROPIC_DEFAULT_SONNET_MODEL=claude-sonnet-4-6
체감 라우팅은 이렇게 잡으면 무난해요.
- 기본 개발 세션: Sonnet 4.6
- 설계가 길어지는 작업:
opusplan - 멀티파일 리팩터링·긴 세션·화면 분석: Opus 4.7
- 배치 처리·초벌 코드: Sonnet 4.6 또는 Haiku 4.5
Claude Code 설치나 기본 조작이 아직 헷갈리면 Claude Code 사용법: 설치부터 첫 실행까지 5분 가이드부터 한 번 훑고 오세요. 모델 전환 명령도 그 다음이 훨씬 편해져요.
기본값을 한 주만 Sonnet 4.6으로 내려보면 청구 대시보드부터 차이가 느껴져요. 같은 트래픽이라도 짧은 작업이 차지하는 비중이 7~8할이라, Sonnet이 받는 호출 수가 그대로 단가 절감으로 이어지더라고요. 어려운 구간만 /model opus로 한 번씩 올리는 정도로도 일주일 누적 비용이 30% 안팎까지 떨어져요.
벤치마크는 올랐는데 체감이 꼬인 이유
2026년 4월 하순에 나왔던 “왜 이렇게 별로지?” 반응은 모델 자체 문제만은 아니었어요. Anthropic이 2026-04-23 공개한 포스트모텀을 보면 Claude Code 쪽 이슈가 세 갈래로 겹쳤거든요.
모델 하나만 바꿨는데 갑자기 멍청해진 것처럼 느껴졌다면 이상한 게 아니죠?
| 날짜 | 무슨 일이 있었나 | 체감 증상 |
|---|---|---|
| 2026-03-04 | 기본 추론 노력 레벨을 high에서 medium으로 낮춤 |
똑똑함이 줄고 응답만 빨라진 느낌 |
| 2026-03-26 | 1시간 넘게 쉬었다 돌아온 세션에서 이전 추론 흔적(old thinking) 정리 버그 발생 | 기억을 잃고 반복하거나 엉뚱한 도구 선택 |
| 2026-04-16 | 장황함 줄이려는 system prompt 문구 추가 | 코드 품질 하락, Opus 4.7도 영향 |
| 2026-04-20 | v2.1.116(세 이슈 모두 수정된 첫 버전) 기준 해결 | 재테스트 시점 |
| 2026-04-23 | 포스트모텀 공개, 구독자 usage limits reset | 초기 반응을 다시 읽어야 하는 구간 |
여기서 중요한 건 두 가지예요. 첫째, 출시 직후에 읽은 불만 글을 지금 체감과 그대로 겹치면 안 돼요. 둘째, Opus 4.7은 지시를 더 문자 그대로 따르는 편이라 4.6 때 대충 통하던 프롬프트가 그대로는 안 먹힐 수 있어요. 처음엔 단순 리팩터링만 시켜도 자꾸 반박하길래 짜증이 났는데, 요구 결과·금지 범위·검증 기준을 한 번에 적으니 훨씬 덜 삐끗하더라고요.
지금 다시 테스트할 때는 이 순서가 편해요.
- 예전과 같은 프롬프트로 다시 돌려요
- 긴 세션은 30~40분 단위로 체크포인트를 끊어요
- “무엇을 만들지”와 “무엇은 하지 말지”를 같이 써요
- launch week 체감과 현재 체감을 섞지 말아요
Anthropic 밖 비교까지 같이 보고 싶으면 Gemini 3 vs Claude Opus 4.7 코딩 비교: 실제 작업 5가지로 검증도 이어서 보면 좋아요. 벤치마크 숫자와 일상 워크플로우 체감이 왜 다르게 오는지 같이 보기 좋거든요.
자주 묻는 질문
Q1. SWE-bench Verified, 실제 GitHub 이슈 해결형 코딩 벤치마크에서 Sonnet 4.6도 높은데 왜 Opus 4.7을 쓰나요?
A: Anthropic 자체 발표 기준으로 SWE-bench Verified는 Sonnet 4.6이 79.6%, Opus 4.7이 87.6%, 약 8%포인트 차이예요. 단일 함수·짧은 리뷰·분류처럼 한 번에 끝나는 작업에선 이 갭이 거의 안 보여요. 갭이 벌어지는 건 멀티파일 리팩터링·장기 에이전트 세션·고해상도 화면 분석처럼 사고를 길게 잡고 가야 하는 구간이에요.
Q2. Opus 4.7 가격이 그대로라는데 왜 청구액이 더 나오나요?
A: 기본 단가는 Opus 4.6과 같아도 tokenizer와 응답 길이 때문에 체감 비용이 달라질 수 있어요. 같은 system prompt를 count_tokens로 직접 재보면 어디서 더 닳는지 바로 보여요.
Q3. Claude Code 기본 모델을 Sonnet 4.6으로 바꾸면 품질이 많이 떨어지나요?
A: 파일 1~3개 수정, 짧은 함수 작성, 일반 디버깅에서는 체감 차이가 작을 가능성이 커요. 큰 리팩터링이나 오래 끄는 세션에서만 Opus로 올리는 쪽이 대개 효율적이죠.
Q4. Opus 4.7이 지시를 안 따르고 자꾸 반박하는데 정상인가요?
A: 출시 직후엔 그런 체감 보고가 많았고, Claude Code 쪽 이슈도 겹쳐 있었어요. 지금은 먼저 같은 프롬프트를 다시 테스트하고, 결과물 형식·금지 범위·검증 기준을 더 빡빡하게 적어보세요.
Q5. Bedrock나 Vertex AI에서 opus 별칭만 쓰면 바로 Opus 4.7인가요?
A: 2026-04-25 기준 Claude Code 공식 문서에선 아니라고 봐야 해요. Anthropic API에선 opus가 Opus 4.7, sonnet이 Sonnet 4.6으로 풀리지만, Bedrock·Vertex AI·Foundry는 full model name을 직접 넣는 편이 안전해요.
다음 단계
이번 주는 Claude Code 기본 모델을 Sonnet 4.6으로 내려두고, 5개 이상 파일을 만지는 작업만 Opus 4.7로 올려보세요. 다른 모델이랑도 같이 재보고 싶으면 GPT-5.5 vs Claude Opus 4.7: 터미널 작업과 코드베이스 리팩터링 어디에 쓸지까지 이어서 보면 선택 기준이 더 빨라져요.
관련 글: Claude Code 월 사용료 줄이기
관련 글: Claude Code 컨텍스트 확장
관련 글: 인디 해커용 AI 빌더 선택